40 Reporting Your Analysis
This chapter provides a concise, reproducible workflow for reporting a data analysis in business and social science contexts. We demonstrate end-to-end reporting elements you’d typically see in a professional manuscript (marketing, finance, management), complete with diagnostic checks, robust/clustered standard errors, model comparison, and high-quality tables/figures.
40.1 Recommended Structure
40.1.1 Phase 1: Exploratory Data Analysis (EDA)
Understanding Your Data Landscape
Before embarking on any modeling endeavor, immerse yourself thoroughly in your data. Exploratory data analysis serves as the foundation upon which all subsequent analysis rests. This critical phase allows you to develop intuition about your dataset, identify potential challenges, and formulate preliminary hypotheses that will guide your modeling decisions.
Visual Exploration and Data Visualization
Begin by creating a comprehensive suite of visualizations that reveal the character and structure of your data. Univariate plots such as histograms, density plots, and boxplots illuminate the distribution of individual variables, revealing whether they follow normal, skewed, bimodal, or other distribution patterns. These visualizations immediately expose the presence of extreme values and help you understand the central tendency and spread of each variable.
For continuous variables, construct detailed histograms with appropriate bin widths to capture the true shape of the distribution. Overlay kernel density estimates to smooth out the discrete nature of histograms and reveal underlying patterns. Complement these with boxplots that succinctly display the five-number summary while making outliers immediately visible.
For categorical variables, develop bar charts and frequency tables that show the distribution of observations across categories. Pay particular attention to class imbalance, as severely imbalanced categories can create challenges for certain modeling approaches and may require special handling techniques such as stratified sampling or synthetic minority oversampling.
Transition next to bivariate and multivariate visualizations that expose relationships between variables. Scatter plots reveal correlations, non-linear relationships, and interaction effects between continuous variables. When examining the relationship between a continuous outcome and categorical predictors, construct side-by-side boxplots or violin plots that simultaneously display distribution shape and central tendency across groups.
Correlation matrices presented as heatmaps provide an at-a-glance understanding of linear relationships among all continuous variables in your dataset. Use color gradients thoughtfully to make strong positive and negative correlations immediately apparent. Augment simple correlation coefficients with scatter plot matrices that allow you to visually inspect the nature of each pairwise relationship.
For more complex multivariate patterns, consider dimension reduction techniques such as principal component analysis (PCA) or t-distributed stochastic neighbor embedding (t-SNE). While these methods will be explored more rigorously later, preliminary visualizations in reduced dimensional space can reveal clustering, separation between groups, or other high-dimensional structure that would otherwise remain hidden.
Preliminary Statistical Results
Complement your visual exploration with descriptive statistics that quantify the properties you’ve observed graphically. Calculate measures of central tendency including means, medians, and modes for each variable. Assess spread through standard deviations, interquartile ranges, and ranges. For skewed distributions, report robust statistics that are less sensitive to extreme values.
Construct detailed contingency tables for categorical variables, including both counts and proportions. Calculate marginal and conditional distributions to understand how categories relate to one another. For key relationships of interest, compute preliminary effect sizes or correlation coefficients to quantify the strength of associations.
Perform initial hypothesis tests where appropriate, but interpret these exploratory results with appropriate caution. At this stage, you are generating hypotheses rather than testing pre-specified ones, so traditional significance thresholds should be applied conservatively. Consider adjusting for multiple comparisons if you conduct numerous exploratory tests, or better yet, clearly distinguish between confirmatory and exploratory findings in your narrative.
Identifying Interesting Patterns, Structure, and Features
As you explore your data, remain vigilant for unexpected patterns that might inform your modeling strategy or reveal important substantive insights. Look for evidence of subgroups or clusters within your data that might suggest the need for hierarchical models, mixture models, or stratified analyses. Notice whether relationships between variables appear consistent across the full range of the data or if they change in character at certain thresholds.
Temporal patterns deserve special attention if your data have any time-series component. Plot variables across time to identify trends, seasonality, or structural breaks that might violate independence assumptions or require specialized time-series modeling approaches. Even in cross-sectional data, consider whether unobserved temporal factors might have introduced systematic patterns.
Geographic or spatial patterns should similarly be explored if your data have spatial attributes. Map-based visualizations can reveal spatial autocorrelation or clustering that standard models might miss. If present, such patterns may necessitate spatial statistical methods that explicitly model dependence structures.
Pay attention to the relationship between variance and mean across groups or conditions. Heteroscedasticity, where the variability of your outcome changes systematically with predictor values, will violate key assumptions of many standard models and may require variance-stabilizing transformations or more flexible modeling frameworks.
Outlier Detection and Characterization
Devote substantial attention to identifying and understanding outliers, which are observations that differ markedly from the overall pattern in your data. Begin with univariate outlier detection using methods such as the \(1.5 \times IQR\) rule for boxplots, which flags points falling more than 1.5 times the interquartile range beyond the first or third quartile. For normally distributed data, consider threshold rules based on standard deviations, such as flagging observations more than three standard deviations from the mean.
Extend your outlier analysis to the multivariate space, where observations that appear unremarkable in any single dimension may nonetheless be anomalous in their combination of values. Mahalanobis distance measures how far each observation lies from the center of the multivariate distribution, accounting for correlations between variables. Cook’s distance and other influence diagnostics, while typically associated with model diagnostics, can also be calculated at this exploratory stage to identify observations that might exert disproportionate influence on subsequent analyses.
Crucially, resist the temptation to automatically discard outliers. Instead, investigate each carefully to understand its origin and nature.
Is it a data entry error that should be corrected?
Is it a legitimate but rare event that contains valuable information?
Does it represent a different population that should be analyzed separately?
Document your decisions transparently, presenting results both with and without questionable observations when appropriate, so readers can assess the robustness of your conclusions.
Consider the domain context when evaluating outliers. In some fields, extreme values may be the most scientifically interesting observations, while in others they may represent measurement errors or irrelevant anomalies. Consult with subject matter experts to properly interpret unusual observations and make informed decisions about their treatment.
40.1.2 Phase 2: Model Selection and Specification
Articulating Model Assumptions
Every statistical model rests on a foundation of assumptions, and making these explicit is essential for proper interpretation and assessment of your results. Begin by clearly stating the distributional assumptions your model makes about the outcome variable. Does your model assume normally distributed errors, or are you working within a generalized linear model framework that allows for binomial, Poisson, or other distributional families?
Detail the assumptions about the relationship between predictors and outcome. Most commonly, models assume linearity in parameters, meaning that the expected outcome changes by a constant amount for each unit change in a predictor (possibly after appropriate transformation or link function). If your model permits non-linear relationships through polynomial terms, splines, or other flexible forms, explain the functional form you’ve adopted and why.
Independence assumptions warrant careful consideration. Standard regression assumes that observations are independent of one another, but this is frequently violated in practice by clustering (students within schools, measurements within individuals), spatial dependence, or temporal autocorrelation. If such dependencies exist in your data structure, acknowledge them explicitly and describe how your model accounts for them, whether through mixed effects, robust standard errors, or specialized correlation structures.
Homoscedasticity, the assumption of constant error variance, should be stated and later verified. Many standard inferential procedures assume that the variance of your outcome does not depend on predictor values or fitted values, though weighted regression or generalized linear models can accommodate heteroscedastic errors when this assumption is untenable.
Additional assumptions relevant to specific methods should be documented. For causal inference, state clearly what identification assumptions are necessary for causal interpretation, such as ignorability, no unmeasured confounding, or valid instrumental variables. For time series models, describe stationarity assumptions. For machine learning approaches, discuss assumptions about the relationship between training and test data distributions.
Justifying Your Modeling Approach
After articulating assumptions, provide a compelling rationale for why your chosen model is the most appropriate tool for addressing your research question. Connect the model selection directly to your scientific objectives. If your goal is prediction, emphasize the model’s predictive performance and its ability to generalize to new data. If your goal is inference about specific parameters, justify how the model structure allows for valid and efficient estimation of those parameters.
Consider the nature of your outcome variable in justifying your approach. Continuous outcomes measured on an interval or ratio scale typically call for linear regression or its extensions, while binary outcomes necessitate logistic regression or other classification methods. Count data often require Poisson or negative binomial regression, while time-to-event data demand survival analysis techniques. Ordinal outcomes merit specialized methods that respect the ordered nature of categories.
Discuss how your model handles the specific challenges present in your data. If you have high-dimensional data with more predictors than observations, explain your choice of regularization method such as ridge, lasso, or elastic net regression. If multicollinearity is a concern, describe how your approach mitigates its effects, whether through variable selection, principal component regression, or Bayesian methods with informative priors.
Address computational considerations when relevant. Some modeling approaches that are theoretically ideal may be computationally intractable for large datasets, while others scale efficiently. If you’ve made tradeoffs between statistical optimality and computational feasibility, acknowledge this transparently and describe any steps taken to validate that the chosen approach provides adequate performance.
Compare your chosen model to reasonable alternatives, explaining why you’ve selected one approach over others. This comparative discussion demonstrates that you’ve thoughtfully considered multiple options rather than defaulting to a familiar method. You might compare parametric versus non-parametric approaches, frequentist versus Bayesian frameworks, or simple versus complex model structures, weighing their relative advantages and limitations in your specific context.
Considering Interactions, Collinearity, and Dependence
Interaction effects represent situations where the effect of one predictor on the outcome depends on the value of another predictor. During model specification, consider whether substantive theory suggests important interactions, and explore whether your exploratory analysis revealed evidence of effect modification. Interaction terms can substantially improve model fit and provide crucial scientific insights, but they also increase model complexity and can make interpretation challenging.
When including interactions, think carefully about whether to also include the constituent main effects (you almost always should, to maintain the principle of marginality), and consider centering continuous variables before forming interaction terms to reduce collinearity and aid interpretation. Visualize predicted values across different combinations of interacting variables to help readers understand these complex relationships.
Multicollinearity, the presence of strong linear relationships among predictors, can create serious problems for parameter estimation and interpretation. Severely collinear predictors lead to unstable coefficient estimates with inflated standard errors, making it difficult to isolate the individual effect of any single predictor. Assess collinearity using variance inflation factors (VIF), with values exceeding 5 or 10 typically indicating problematic levels.
When high collinearity is detected, several remedial strategies exist. You might remove one of a highly correlated pair of predictors based on theoretical considerations or measurement quality. Alternatively, combine collinear predictors into composite scores or indices that capture their shared information. Regularization methods such as ridge regression explicitly address collinearity by shrinking coefficient estimates. In some cases, severe collinearity simply reflects reality and must be acknowledged as a limitation, particularly when you need to include certain predictors for theoretical completeness despite their intercorrelation.
Dependence structures in your data require special modeling approaches. For clustered data, where observations are nested within groups, mixed effects (multilevel or hierarchical) models partition variance into within-group and between-group components and account for the correlation among observations from the same cluster. Specify both fixed effects that represent average relationships and random effects that allow these relationships to vary across clusters.
For longitudinal data with repeated measurements on the same units, consider growth curve models, generalized estimating equations (GEE), or transition models depending on your research question. Each approach handles the correlation among repeated measures differently and allows for different types of inference, so select the framework that best matches your substantive goals.
Spatial or network dependence calls for specialized models that explicitly represent connections between observations. Spatial autoregressive models, geographically weighted regression, or network autocorrelation models may be appropriate depending on the structure of spatial or social relationships in your data.
40.1.3 Phase 3: Model Fitting and Diagnostic Assessment
Evaluating Overall Model Fit
After estimating your model, systematically evaluate how well it fits the observed data. Begin with summary statistics that quantify the proportion of variance explained. For linear models, the coefficient of determination (\(R^2\)) indicates what fraction of outcome variance is captured by your predictors, while adjusted \(R^2\) penalizes model complexity to discourage overfitting. Recognize that while \(R^2\) provides a useful summary, it doesn’t tell the whole story about model adequacy, and even low \(R^2\) values can be scientifically important if they represent relationships that are difficult to predict.
For generalized linear models, report appropriate pseudo-\(R^2\) measures such as McFadden’s, Nagelkerke’s, or Tjur’s \(R^2\), keeping in mind that these lack the direct interpretation of classical \(R^2\). Log-likelihood values and deviance statistics provide information about how well the model’s probability distribution matches the data, with comparisons to null or saturated models offering context for interpretation.
Information criteria including Akaike Information Criterion (AIC) and Bayesian Information Criterion (BIC) balance goodness of fit against model complexity, rewarding fit while penalizing the inclusion of additional parameters. These are particularly valuable for comparing non-nested models, though differences of less than 2-3 units are generally considered negligible. BIC penalizes complexity more heavily than AIC and tends to favor simpler models, especially with large sample sizes.
For models intended for prediction, assess predictive performance using metrics appropriate to your outcome type. For continuous outcomes, examine mean squared error, root mean squared error, or mean absolute error. For binary outcomes, consider accuracy, sensitivity, specificity, positive and negative predictive values, area under the ROC curve (AUC), and calibration metrics. Critically, evaluate predictive performance on held-out data not used for model training to obtain honest estimates of generalization performance.
Conduct formal goodness-of-fit tests where appropriate. The Hosmer-Lemeshow test for logistic regression, the deviance test for generalized linear models, or omnibus tests for model specification each provide statistical assessments of model adequacy, though remember that with large sample sizes, these tests may reject even models that fit adequately for practical purposes.
Verifying Model Assumptions Through Residual Analysis
Residual analysis forms the cornerstone of model diagnostics, as residuals (i.e., the differences between observed and fitted values) should exhibit certain properties if model assumptions hold. If your model is correctly specified and assumptions are satisfied, residuals should appear as random noise without systematic patterns.
Begin with residual plots that display residuals against fitted values. In a well-fitting model, this plot should show a random cloud of points with no discernible pattern, constant spread across the range of fitted values, and no systematic curvature. A funnel shape, where spread increases or decreases with fitted values, suggests heteroscedasticity. Curved patterns indicate that the assumed functional form may be incorrect and that transformations or additional predictors might improve the model.
For generalized linear models, use appropriate residuals such as deviance, Pearson, or quantile residuals rather than raw residuals, as these better approximate the expected properties under the model assumptions. Deviance residuals are particularly useful for assessing overall model fit, while Pearson residuals help evaluate the variance assumption.
Construct residual plots against each predictor variable to identify whether any individual predictor’s relationship with the outcome is misspecified. Non-random patterns in these plots suggest that the predictor may require transformation, that its effect may be non-linear, or that it may interact with other variables.
Q-Q (quantile-quantile) plots compare the distribution of residuals to the theoretical distribution assumed by your model, typically the normal distribution for linear regression. Points should fall approximately along a straight diagonal line if the distributional assumption is satisfied. Systematic departures from linearity, particularly in the tails, indicate non-normality. Light-tailed distributions (fewer extreme values than expected under normality) produce S-shaped patterns, while heavy-tailed distributions (more extreme values) create inversely S-shaped patterns.
For time series or spatially structured data, examine residual autocorrelation through autocorrelation function (ACF) plots or spatial correlograms. Significant autocorrelation in residuals indicates that your model has failed to account for temporal or spatial dependence, suggesting the need for more sophisticated modeling approaches that explicitly model correlation structures.
Identify influential observations using diagnostic measures such as Cook’s distance, DFBETAS, DFFITS, and leverage values. Influential points are those whose inclusion or exclusion would substantially alter model estimates or predictions. High leverage points have unusual predictor values that give them the potential for influence, while high influence points actually do substantially affect the fitted model. Investigate influential observations carefully, determining whether they represent errors, exceptional cases worthy of separate analysis, or legitimate data that should be retained.
Assess the variance inflation in parameter estimates due to collinearity by examining condition indices or variance decomposition proportions in addition to variance inflation factors. These diagnostics help you understand which specific parameters are most affected by collinearity and whether the instability is severe enough to warrant remedial action.
Test for heteroscedasticity formally using the Breusch-Pagan test, White test, or other appropriate diagnostics depending on your model type. If heteroscedasticity is detected, consider whether variance-stabilizing transformations, weighted least squares, or robust standard error estimators are appropriate remedies.
For mixed effects models, examine residuals at each level of the hierarchy. Inspect level-1 (within-group) residuals for the usual regression diagnostics, and additionally examine level-2 (group-level) residuals and random effects to assess whether higher-level assumptions are satisfied and to identify outlying clusters.
When assumption violations are detected, consider their practical severity carefully. Minor violations may have negligible impact on inference, particularly with large samples where central limit theorem properties provide robustness. Severe violations require remedy through data transformation, alternative modeling approaches, robust methods, or explicit acknowledgment as a limitation.
40.1.4 Phase 4: Inference and Prediction
Drawing Valid Statistical Inferences
With a well-fitting model in hand, turn your attention to statistical inference about parameters of interest and the relationships they represent. Begin by reporting point estimates for all relevant parameters, including regression coefficients, odds ratios, hazard ratios, or other effect measures appropriate to your model type. Present these with appropriate measures of uncertainty, typically confidence intervals and p-values from hypothesis tests.
Interpret each parameter estimate in the context of your research question and in language accessible to your intended audience. For linear regression coefficients, explain the expected change in the outcome associated with a one-unit change in the predictor, holding other variables constant. For logistic regression, interpret odds ratios or convert to more intuitive probability scales for specific covariate values. For survival models, explain hazard ratios in terms of relative risk over time.
Attend carefully to the distinction between statistical significance and practical significance. Statistically significant effects may be too small to matter in practice, particularly with large samples, while non-significant effects may still be substantively important, especially when confidence intervals are wide due to limited power. Report and discuss both the magnitude and precision of estimates rather than focusing exclusively on whether p-values fall below arbitrary thresholds.
Consider the multiple testing problem if you’re conducting numerous hypothesis tests. When testing many hypotheses simultaneously, some will appear significant purely by chance. Address this through appropriate multiple testing corrections such as Bonferroni, Holm, or false discovery rate (FDR) methods, or through a hierarchical testing strategy that prioritizes certain comparisons. Alternatively, distinguish clearly between confirmatory tests of pre-specified hypotheses and exploratory analyses that generate hypotheses for future research.
For predictive models, generate predictions for new observations or for specific covariate profiles of interest. Provide prediction intervals that appropriately capture uncertainty, recognizing that prediction uncertainty includes both estimation uncertainty about parameters and inherent residual variation in individual observations. Visualize predictions across the range of key predictors to help readers understand model implications.
Exploring Alternative Approaches to Support Inference
Strengthen your inferences by demonstrating robustness through alternative analytical approaches. A finding that persists across multiple reasonable modeling strategies is more credible than one that depends critically on specific modeling choices. This triangulation of evidence provides readers with greater confidence in your conclusions.
Conduct sensitivity analyses that explore how results change under different assumptions. Fit variants of your model that include or exclude potential confounders, use different functional forms for continuous predictors, apply different transformations to the outcome, or employ alternative link functions. If conclusions remain substantively similar across these variations, you can be more confident in their validity. If results are sensitive to specific modeling choices, acknowledge this and discuss which specification is most defensible based on theory and empirical evidence.
For causal inference questions, implement multiple analytical strategies if possible. Combine regression adjustment with propensity score methods, instrumental variables, difference-in-differences, or regression discontinuity designs depending on your data structure and research design. Agreement across methods that rely on different identifying assumptions substantially strengthens causal claims.
Employ resampling methods such as bootstrap or permutation tests to validate your inferential conclusions, particularly when sample sizes are modest or distributional assumptions are questionable. The bootstrap provides a way to estimate sampling distributions and standard errors without relying on parametric assumptions, while permutation tests offer exact significance tests for certain hypotheses.
Conduct subgroup analyses to examine whether relationships are consistent across different populations or contexts within your data. While these are exploratory and should be interpreted cautiously due to reduced power and multiple testing concerns, they can reveal important heterogeneity in effects and generate hypotheses about effect moderation that deserve investigation in future studies.
Implement cross-validation or other hold-out validation procedures for predictive models to honestly assess generalization performance. K-fold cross-validation, leave-one-out cross-validation, or train-test splits allow you to evaluate how well your model performs on data it hasn’t seen during training. This is essential for claims about predictive utility and for comparing the predictive performance of different modeling approaches.
If you have access to multiple datasets addressing similar questions, consider replication analyses that fit your model to independent data. Successful replication provides the strongest possible evidence for the robustness and generalizability of your findings, while failures to replicate may indicate that initial results were sample-specific or resulted from chance variation.
For Bayesian analyses, conduct prior sensitivity analyses that examine how posterior inferences change under different prior specifications. If conclusions are similar under a range of reasonable priors, inference is robust to prior specification. If posteriors are highly sensitive to prior choice, either collect more data to allow the likelihood to dominate or acknowledge that definitive conclusions require stronger prior information.
40.1.5 Phase 5: Conclusions and Recommendations
Synthesizing Findings into Actionable Recommendations
In concluding your analysis, synthesize your findings into clear, actionable recommendations that directly address the original research questions or practical problems that motivated the investigation. Avoid simply restating results; instead, interpret their meaning and implications for theory, policy, or practice.
Connect your statistical findings back to the substantive domain, explaining what your results mean for real-world phenomena. If you’ve found that a particular intervention has a significant positive effect, discuss what decision-makers should do with this information. If you’ve built a predictive model, explain how it should be deployed and what level of performance users can expect in practice.
Prioritize your recommendations by importance and strength of evidence. Some findings will be central to your research questions and supported by robust evidence across multiple analyses, while others may be more peripheral or tentative. Help readers understand which conclusions are most secure and which require additional confirmation before being acted upon.
Acknowledge uncertainty in your recommendations. Statistical analysis rarely provides absolute certainty, and honest acknowledgment of uncertainty better serves decision-makers than false precision. Describe the range of plausible effects indicated by confidence intervals and discuss how remaining uncertainty might affect decisions.
If your analysis revealed unexpected findings, discuss their potential significance and implications for existing theory or practice. Surprising results often represent the most important scientific contributions, but they also require more scrutiny and replication before being accepted with high confidence.
Consider differential implications for different stakeholders or contexts. A finding that suggests one course of action for one group might have different implications for another, and careful analysis should recognize this heterogeneity in drawing conclusions.
Acknowledging Limitations with Specificity and Candor
Every analysis has limitations, and comprehensive acknowledgment of these limitations actually strengthens rather than weakens your work by demonstrating careful scientific reasoning and helping readers appropriately calibrate their confidence in your conclusions. Move beyond generic limitations to provide specific, honest assessment of factors that may limit the validity or generalizability of your findings.
Discuss limitations related to your data source and sampling. Is your sample representative of the population to which you wish to generalize, or might selection bias limit external validity? Are there important subgroups underrepresented or absent from your data? Does non-response or attrition introduce potential bias? Are key variables measured with error or missing for substantial proportions of observations?
Address methodological limitations in your analytical approach. Which assumptions of your chosen model are most questionable in your particular application? Are there known alternatives that might have advantages you couldn’t exploit due to data constraints or computational limitations? Does the observational nature of your data limit causal inference, even if you’ve attempted to address confounding through statistical adjustment?
Consider limitations in measurement and operationalization. Do your variables capture the theoretical constructs of interest with high fidelity, or are they imperfect proxies? Are there important dimensions of concepts that your measures don’t capture? Would different but equally defensible operationalizations lead to different conclusions?
Acknowledge temporal limitations. For cross-sectional data, note that you observe relationships at a single time point and cannot make claims about causal ordering or temporal dynamics. For longitudinal data, discuss whether your observation period is long enough to capture relevant changes and whether patterns might differ over longer time horizons.
Discuss limitations related to model complexity and specification. Have you potentially omitted important confounders or moderators due to data unavailability? Does your model impose functional form assumptions that, while reasonable, may not perfectly capture reality? Have you prioritized interpretability over predictive performance, or vice versa, and how might this choice limit certain uses of your findings?
For predictive models, clearly delineate the conditions under which predictions should be trusted and situations where the model may perform poorly. Discuss the training data’s representativeness and how concept drift or distribution shift might affect performance when the model is deployed in different contexts or time periods.
Address limitations in statistical power if applicable. Underpowered studies may fail to detect truly important effects, and confidence intervals may be too wide to provide useful guidance. Non-significant findings in underpowered studies should be interpreted as inconclusive rather than as evidence of null effects.
Charting a Path Forward: Future Research Directions
Conclude by outlining specific steps that could address the limitations you’ve identified and advance understanding beyond what your current analysis achieved. This forward-looking discussion demonstrates scientific maturity and provides a roadmap for continuing research on important questions.
For data-related limitations, describe what improved data collection efforts would look like. Should future studies employ different sampling strategies to improve representativeness? Would longitudinal designs that track individuals over time provide stronger evidence than cross-sectional data? Are there key variables that should be measured but weren’t available in your data? Would larger sample sizes enable detection of more subtle effects or more complex modeling?
Recommend methodological innovations or alternative analytical approaches that might overcome current limitations. Are there emerging statistical methods that would better address the particular challenges your data present? Would experimental or quasi-experimental designs provide stronger causal evidence? Could different modeling frameworks accommodate complexities that your current approach handles imperfectly?
Suggest directions for extending your findings. What related research questions naturally follow from your results? Are there important moderators or boundary conditions that should be explored? Would replication in different populations or contexts test the generalizability of your findings? Are there theoretical mechanisms linking your variables that require further investigation?
For applied work, discuss how implementation research could assess the effectiveness of your recommendations in practice. Statistical findings that seem promising in analysis may encounter challenges when deployed in real-world contexts, and careful evaluation of implementation is crucial for evidence-based practice.
Consider interdisciplinary connections that might enrich future investigation of your research questions. Would combining your quantitative approach with qualitative methods provide richer understanding? Could insights from other disciplines inform better model specification or theoretical development?
If your work identified measurement limitations, suggest how instrument development or validation studies could improve future research. Better measurement is often the key to scientific progress, and acknowledging measurement challenges while proposing solutions contributes meaningfully to your field.
Discuss how emerging data sources or technologies might enable future research that wasn’t possible for your current analysis. Could sensor data, administrative records, natural language processing of text data, or other innovations provide new windows into your research questions?
Finally, contextualize your work within the broader scientific enterprise. Position your analysis as one contribution within an accumulating body of evidence, acknowledging what remains to be learned and how the field should collectively move forward to advance understanding.
This expanded structure provides a comprehensive framework for conducting and presenting rigorous statistical analysis, emphasizing transparency, methodological awareness, and careful reasoning at every stage of the research process.
40.3 Exploratory Analysis
We begin with EDA to understand variable distributions, relationships, and potential data issues (outliers, missingness, skew)3. The jtools::movies dataset offers a realistic setting with continuous and discrete variables relevant to business/creative outcomes.
Key steps:
Inspect distributions (histograms/densities)
Examine pairwise relationships (scatterplots, correlation)
Flag outliers and influential observations
data(movies, package = "jtools")
# Minimal wrangling for illustration
movies_small <- movies %>%
select(metascore, budget, us_gross, year, runtime) %>%
filter(complete.cases(.))
summary(movies_small)
#> metascore budget us_gross year
#> Min. : 16.00 Min. : 11622 Min. :4.261e+04 Min. :1971
#> 1st Qu.: 52.00 1st Qu.: 19543169 1st Qu.:3.168e+07 1st Qu.:1998
#> Median : 64.00 Median : 40452872 Median :7.318e+07 Median :2004
#> Mean : 63.01 Mean : 60831325 Mean :1.215e+08 Mean :2002
#> 3rd Qu.: 75.00 3rd Qu.: 89567622 3rd Qu.:1.530e+08 3rd Qu.:2009
#> Max. :100.00 Max. :461435929 Max. :1.772e+09 Max. :2013
#> runtime
#> Min. :1.333
#> 1st Qu.:1.667
#> Median :1.850
#> Mean :1.923
#> 3rd Qu.:2.100
#> Max. :3.367
# Distribution plots (log scale for highly skewed financials)
library(tidyr)
movies_long <- movies_small %>%
pivot_longer(cols = c(metascore, budget, us_gross, runtime),
names_to = "variable", values_to = "value")
ggplot(movies_long, aes(value)) +
facet_wrap(~ variable, scales = "free") +
geom_histogram(bins = 30, fill = "#3c8dbc", color = "white") +
scale_x_continuous(labels = scales::label_number(scale_cut = scales::cut_short_scale())) +
labs(title = "Distributions of Key Variables",
x = NULL, y = "Count") +
theme_bw(base_size = 12)
# Pairwise relationships: simple scatter matrix
if (requireNamespace("GGally", quietly = TRUE)) {
GGally::ggpairs(
movies_small %>% mutate(across(c(budget, us_gross), log1p)),
columns = c("metascore","budget","us_gross","runtime","year"),
upper = list(continuous = GGally::wrap("cor", size = 3)),
lower = list(continuous = GGally::wrap("points", alpha = .5, size = .7)),
diag = list(continuous = GGally::wrap("barDiag", bins = 20))
) + theme_bw(base_size = 10)
}
# Quick correlation table (with log transforms for skewed $ variables)
cor_mat <- movies_small %>%
mutate(across(c(budget, us_gross), log1p)) %>%
select(metascore, budget, us_gross, runtime, year) %>%
cor(use = "pairwise.complete.obs")
round(cor_mat, 3)
#> metascore budget us_gross runtime year
#> metascore 1.000 -0.168 0.105 0.197 -0.126
#> budget -0.168 1.000 0.596 0.378 0.017
#> us_gross 0.105 0.596 1.000 0.245 -0.309
#> runtime 0.197 0.378 0.245 1.000 -0.057
#> year -0.126 0.017 -0.309 -0.057 1.000
# Outlier & influence screening (pre-model)
base_fit <- lm(metascore ~ log1p(budget) + log1p(us_gross) + runtime + year, data = movies_small)
infl <- influence.measures(base_fit)
summary(infl)
#> Potentially influential observations of
#> lm(formula = metascore ~ log1p(budget) + log1p(us_gross) + runtime + year, data = movies_small) :
#>
#> dfb.1_ dfb.l1() dfb.l1(_ dfb.rntm dfb.year dffit cov.r cook.d hat
#> 20 -0.05 -0.06 0.06 -0.02 0.05 -0.12 0.96_* 0.00 0.00
#> 40 0.08 0.06 -0.04 0.05 -0.09 -0.16 0.96_* 0.01 0.00
#> 44 0.05 -0.08 0.06 0.01 -0.05 0.12 1.03_* 0.00 0.03_*
#> 62 0.09 0.13 -0.05 0.07 -0.10 -0.22 0.97_* 0.01 0.01
#> 95 0.02 0.03 0.01 0.10 -0.02 -0.16 0.97_* 0.01 0.00
#> 102 0.00 0.00 0.00 0.00 0.00 -0.01 1.02_* 0.00 0.02_*
#> 106 -0.01 -0.01 0.00 0.01 0.01 0.02 1.02_* 0.00 0.02
#> 110 -0.01 0.00 0.01 -0.03 0.01 -0.04 1.02_* 0.00 0.01
#> 112 0.00 0.04 0.00 -0.02 0.00 -0.05 1.02_* 0.00 0.02_*
#> 129 0.00 0.00 0.00 0.00 0.00 0.00 1.02_* 0.00 0.01
#> 133 0.03 0.03 -0.05 -0.02 -0.03 0.06 1.02_* 0.00 0.01
#> 138 0.00 0.18 -0.07 -0.06 -0.01 -0.19 1.03_* 0.01 0.03_*
#> 143 -0.02 0.31 -0.10 -0.06 0.00 -0.34_* 1.04_* 0.02 0.05_*
#> 172 0.25 0.05 -0.14 -0.06 -0.24 0.28_* 1.00 0.02 0.02
#> 205 -0.02 0.40 -0.13 -0.06 0.00 -0.44_* 1.06_* 0.04 0.07_*
#> 230 0.01 0.01 -0.01 0.00 -0.01 0.01 1.02_* 0.00 0.01
#> 237 -0.21 -0.06 0.01 0.12 0.21 -0.26_* 0.98_* 0.01 0.01
#> 239 -0.18 0.14 -0.07 0.05 0.17 -0.30_* 0.97_* 0.02 0.01
#> 271 -0.14 0.04 0.11 -0.14 0.14 0.25_* 0.97_* 0.01 0.01
#> 296 -0.01 -0.02 0.06 0.00 0.01 -0.07 1.02_* 0.00 0.02_*
#> 298 -0.20 -0.11 0.18 0.00 0.20 -0.24_* 0.99 0.01 0.01
#> 329 0.11 0.24 -0.16 -0.03 -0.12 -0.26_* 1.00 0.01 0.02_*
#> 330 0.16 0.22 -0.18 -0.02 -0.16 -0.26_* 0.99 0.01 0.01
#> 350 -0.01 0.00 0.00 0.06 0.01 0.07 1.02_* 0.00 0.02
#> 383 0.00 0.00 0.00 0.01 0.00 0.01 1.02_* 0.00 0.02_*
#> 385 -0.02 0.01 0.01 -0.09 0.02 -0.10 1.03_* 0.00 0.02_*
#> 387 0.04 0.06 -0.16 0.06 -0.03 0.17 1.06_* 0.01 0.05_*
#> 391 0.00 -0.02 0.00 0.00 0.01 0.02 1.02_* 0.00 0.01
#> 408 -0.01 -0.02 0.02 0.01 0.01 -0.02 1.02_* 0.00 0.01
#> 413 0.00 0.00 -0.02 0.01 0.00 0.02 1.02_* 0.00 0.01
#> 454 0.00 0.15 -0.04 -0.01 -0.01 -0.17 1.04_* 0.01 0.03_*
#> 484 -0.06 0.08 0.04 -0.06 0.06 0.17 0.97_* 0.01 0.00
#> 503 -0.07 0.12 -0.09 -0.03 0.06 -0.17 1.02_* 0.01 0.02_*
#> 510 0.00 0.00 0.00 0.00 0.00 0.00 1.02_* 0.00 0.02
#> 515 0.09 0.30 -0.20 -0.04 -0.10 -0.32_* 0.99 0.02 0.02
#> 516 0.01 -0.03 0.01 0.07 -0.01 0.08 1.03_* 0.00 0.02_*
#> 535 -0.13 -0.10 0.14 -0.04 0.13 -0.20 0.96_* 0.01 0.00
#> 551 -0.22 -0.02 0.10 0.04 0.22 -0.24_* 0.99 0.01 0.01
#> 554 -0.03 -0.04 0.11 -0.04 0.03 -0.12 1.04_* 0.00 0.03_*
#> 586 -0.01 0.00 0.04 0.00 0.00 -0.06 1.02_* 0.00 0.02_*
#> 615 0.01 0.04 -0.03 0.00 -0.01 -0.04 1.04_* 0.00 0.03_*
#> 617 0.01 0.01 -0.02 0.00 -0.01 0.02 1.06_* 0.00 0.05_*
#> 618 0.05 0.09 0.04 -0.07 -0.06 -0.19 0.96_* 0.01 0.00
#> 625 0.04 0.09 -0.07 -0.02 -0.05 -0.13 0.97_* 0.00 0.00
#> 639 0.03 -0.01 0.00 0.04 -0.03 0.05 1.03_* 0.00 0.02_*
#> 646 0.05 -0.01 0.02 0.00 -0.06 0.08 1.02_* 0.00 0.02
#> 655 0.02 0.01 0.00 0.04 -0.02 -0.10 0.98_* 0.00 0.00
#> 661 0.07 -0.04 0.03 0.09 -0.08 0.14 1.03_* 0.00 0.03_*
#> 662 0.02 -0.01 0.00 0.04 -0.02 0.05 1.04_* 0.00 0.03_*
#> 673 0.02 0.03 -0.03 0.00 -0.02 0.04 1.02_* 0.00 0.02
#> 683 0.07 0.14 -0.10 -0.14 -0.08 0.20 0.98_* 0.01 0.01
#> 692 0.02 -0.01 -0.01 0.02 -0.01 0.03 1.02_* 0.00 0.02
#> 698 -0.02 -0.03 0.03 0.10 0.02 0.11 1.03_* 0.00 0.02_*
#> 703 -0.04 -0.07 0.10 -0.13 0.04 -0.20 0.98_* 0.01 0.01
#> 721 -0.10 -0.09 0.17 -0.24 0.10 -0.32_* 0.99 0.02 0.02
#> 730 -0.10 0.14 -0.13 0.02 0.10 -0.23 1.01 0.01 0.02_*
#> 731 0.09 0.05 -0.04 0.08 -0.09 -0.16 0.97_* 0.01 0.00
#> 744 0.01 0.00 0.01 0.00 -0.01 0.02 1.02_* 0.00 0.02
#> 759 0.00 0.00 0.00 0.01 0.00 0.01 1.02_* 0.00 0.02
#> 771 0.00 0.00 -0.01 -0.03 0.00 -0.03 1.03_* 0.00 0.02_*
#> 778 0.03 0.01 0.09 -0.15 -0.03 0.20 0.98_* 0.01 0.01
#> 779 -0.10 0.06 0.09 -0.10 0.09 0.21 0.98_* 0.01 0.01
#> 788 0.04 0.05 -0.15 -0.02 -0.03 0.17 1.02_* 0.01 0.02_*
#> 829 0.03 -0.01 0.01 0.00 -0.03 0.04 1.02_* 0.00 0.02
# Flag observations with large Cook's distance or high leverage
diag_df <- tibble(
.cooksd = cooks.distance(base_fit),
.hat = hatvalues(base_fit),
.resid = rstandard(base_fit)
) %>% mutate(id = row_number())
head(diag_df[order(-diag_df$.cooksd),], 10)
#> # A tibble: 10 × 4
#> .cooksd .hat .resid id
#> <dbl> <dbl> <dbl> <int>
#> 1 0.0393 0.0668 -1.66 205
#> 2 0.0233 0.0476 -1.53 143
#> 3 0.0199 0.0178 -2.34 515
#> 4 0.0199 0.0161 -2.46 721
#> 5 0.0176 0.0113 -2.77 239
#> 6 0.0152 0.0165 2.13 172
#> 7 0.0139 0.0107 -2.53 237
#> 8 0.0134 0.0126 -2.29 330
#> 9 0.0134 0.0187 -1.87 329
#> 10 0.0122 0.00869 2.64 27140.4 Model
We illustrate a multiple linear regression model appropriate for continuous outcomes:
\[ y_i = \beta_0+ \beta_1 \log(\mathrm{budget}_i + 1)+ \beta_2 \log(\mathrm{us\_gross}_i + 1)+ \beta_3 \mathrm{runtime}_i+ \beta_4 \mathrm{year}_i+ \varepsilon_i . \]
40.4.1 Assumptions
- Linearity in parameters and approximately linear relationships after transformation
- Independence of errors (or appropriately modeled dependence/clustered SEs)
- Homoskedasticity of errors (or robust SEs)
- Approximately normal errors for t tests/intervals (large-sample robustness often sufficient)
40.4.2 Why this model?
-
metascoreis continuous; OLS is a natural baseline. - Financial variables are skewed; log-transform helps stabilize variance and linearize relationships.
-
yearandruntimecapture secular trends and content length.
40.4.3 Considerations
- Interactions: e.g., does budget effectiveness differ by year?
- Collinearity: budget and gross can be correlated; check VIF.
- Dependence: panel or clustered structures (franchise, studio) may require cluster-robust SEs.
fit <- lm(metascore ~ log1p(budget) + log1p(us_gross) + runtime + year, data = movies_small)
# Core jtools summary (unstandardized)
summ(fit)| Observations | 831 |
| Dependent variable | metascore |
| Type | OLS linear regression |
| F(4,826) | 41.99 |
| R² | 0.17 |
| Adj. R² | 0.16 |
| Est. | S.E. | t val. | p | |
|---|---|---|---|---|
| (Intercept) | 108.91 | 131.81 | 0.83 | 0.41 |
| log1p(budget) | -6.67 | 0.62 | -10.75 | 0.00 |
| log1p(us_gross) | 3.80 | 0.54 | 7.08 | 0.00 |
| runtime | 14.27 | 1.65 | 8.65 | 0.00 |
| year | -0.01 | 0.07 | -0.19 | 0.85 |
| Standard errors: OLS |
# Enhanced jtools summary: standardized coefs, VIFs, semi-partial correlations, CIs
summ(
fit,
scale = TRUE, # standardized betas
vifs = TRUE, # collinearity diagnostics
part.corr = TRUE, # semi-partial (part) correlations
confint = TRUE,
pvals = TRUE
)| Observations | 831 |
| Dependent variable | metascore |
| Type | OLS linear regression |
| F(4,826) | 41.99 |
| R² | 0.17 |
| Adj. R² | 0.16 |
| Est. | 2.5% | 97.5% | t val. | p | VIF | partial.r | part.r | |
|---|---|---|---|---|---|---|---|---|
| (Intercept) | 63.01 | 61.96 | 64.06 | 117.57 | 0.00 | NA | NA | NA |
log1p(budget)
|
-7.81 | -9.24 | -6.38 | -10.75 | 0.00 | 1.84 | -0.35 | -0.34 |
log1p(us_gross)
|
5.15 | 3.73 | 6.58 | 7.08 | 0.00 | 1.84 | 0.24 | 0.22 |
| runtime | 5.02 | 3.88 | 6.16 | 8.65 | 0.00 | 1.17 | 0.29 | 0.27 |
| year | -0.11 | -1.26 | 1.04 | -0.19 | 0.85 | 1.19 | -0.01 | -0.01 |
| Standard errors: OLS; Continuous predictors are mean-centered and scaled by 1 s.d. The outcome variable remains in its original units. |
# Interactions: visualize and test
fit_int <- lm(metascore ~ log1p(budget)*year + log1p(us_gross) + runtime, data = movies_small)
# Create the transformed variable in your dataset
movies_small$log_budget <- log1p(movies_small$budget)
# Fit the model with the new variable
fit_int <- lm(metascore ~ log_budget*year + log1p(us_gross) + runtime,
data = movies_small)
# Now visualize
interactions::interact_plot(fit_int,
pred = year,
modx = log_budget,
interval = TRUE,
plot.points = TRUE) +
theme_bw(base_size = 12)
# Collinearity (car::vif)
car::vif(fit)
#> log1p(budget) log1p(us_gross) runtime year
#> 1.835578 1.841513 1.172572 1.19286240.4.4 Model Fit
We report \(R^2\), adjusted \(R^2\), residual standard error (RSE), and information criteria (AIC/BIC). For nested models, we can use ANOVA; otherwise, compare AIC/BIC, cross-validated error, or out-of-sample performance.
We then examine residuals for normality, heteroskedasticity, and influential points. If assumptions are questionable, prefer heteroskedasticity-robust or cluster-robust standard errors.
broom::glance(fit) %>%
select(r.squared, adj.r.squared, sigma, AIC, BIC, df, nobs)
#> # A tibble: 1 × 7
#> r.squared adj.r.squared sigma AIC BIC df nobs
#> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <int>
#> 1 0.169 0.165 15.4 6915. 6943. 4 831
# Formal tests (use judiciously; they're sensitive to n)
if (requireNamespace("car", quietly = TRUE)) {
car::ncvTest(fit) # non-constant variance test
car::durbinWatsonTest(fit) # autocorrelation test (time ordering needed)
}
#> lag Autocorrelation D-W Statistic p-value
#> 1 0.03649805 1.923838 0.268
#> Alternative hypothesis: rho != 0
lmtest::bptest(fit) # Breusch-Pagan heteroskedasticity test
#>
#> studentized Breusch-Pagan test
#>
#> data: fit
#> BP = 18.909, df = 4, p-value = 0.0008191
# Partial residual plots
if (requireNamespace("car", quietly = TRUE)) {
car::crPlots(fit)
}
40.4.5 Cluster-Robust Standard Errors
When heteroskedasticity or clustering is present, use sandwich estimators:
HC0/HC1/HC2/HC3: robust to heteroskedasticity
Cluster-robust (by firm, school, market, etc.) when errors correlate within clusters
Below: examples using jtools::summ() and lmtest::coeftest() with sandwich.
# Heteroskedasticity-robust SEs for fit
lmtest::coeftest(fit, vcov. = sandwich::vcovHC(fit, type = "HC3"))
#>
#> t test of coefficients:
#>
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 108.910293 145.640262 0.7478 0.4548
#> log1p(budget) -6.669123 0.708027 -9.4193 < 2.2e-16 ***
#> log1p(us_gross) 3.803854 0.552399 6.8861 1.136e-11 ***
#> runtime 14.268967 1.641196 8.6942 < 2.2e-16 ***
#> year -0.012659 0.072085 -0.1756 0.8606
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
# jtools in one line
summ(fit, robust = "HC3", confint = TRUE)| Observations | 831 |
| Dependent variable | metascore |
| Type | OLS linear regression |
| F(4,826) | 41.99 |
| R² | 0.17 |
| Adj. R² | 0.16 |
| Est. | 2.5% | 97.5% | t val. | p | |
|---|---|---|---|---|---|
| (Intercept) | 108.91 | -176.96 | 394.78 | 0.75 | 0.45 |
| log1p(budget) | -6.67 | -8.06 | -5.28 | -9.42 | 0.00 |
| log1p(us_gross) | 3.80 | 2.72 | 4.89 | 6.89 | 0.00 |
| runtime | 14.27 | 11.05 | 17.49 | 8.69 | 0.00 |
| year | -0.01 | -0.15 | 0.13 | -0.18 | 0.86 |
| Standard errors: Robust, type = HC3 |
# Cluster-robust SEs using example data from 'sandwich'
data("PetersenCL", package = "sandwich")
fit2 <- lm(y ~ x, data = PetersenCL)
# Cluster on 'firm'
summ(fit2, robust = "HC3", cluster = "firm")| Observations | 5000 |
| Dependent variable | y |
| Type | OLS linear regression |
| F(1,4998) | 1310.74 |
| R² | 0.21 |
| Adj. R² | 0.21 |
| Est. | S.E. | t val. | p | |
|---|---|---|---|---|
| (Intercept) | 0.03 | 0.07 | 0.44 | 0.66 |
| x | 1.03 | 0.05 | 20.36 | 0.00 |
| Standard errors: Cluster-robust, type = HC3 |
See Table 40.1 for a quick reference:
| Type | Applicable | Usage | Notes/References |
|---|---|---|---|
| const | iid | Homskedastic | Assumes constant variance |
| HC/HC0 | vcovHC | Heteroskedastic | White’s estimator (White 1980) |
| HC1 | vcovHC | Heteroskedastic | DoF correction (J. G. MacKinnon and White 1985) |
| HC2 | vcovHC | Heteroskedastic | Hat-matrix adjustment |
| HC3 | vcovHC | Heteroskedastic | Preferred for small \(n\); hat-matrix adjustment |
| HC4/4m/5 | vcovHC | Heteroskedastic | Leverage-adaptive |
# Another quick demo on built-in data
data(cars)
model <- lm(speed ~ dist, data = cars)
summary(model)
#>
#> Call:
#> lm(formula = speed ~ dist, data = cars)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -7.5293 -2.1550 0.3615 2.4377 6.4179
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 8.28391 0.87438 9.474 1.44e-12 ***
#> dist 0.16557 0.01749 9.464 1.49e-12 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Residual standard error: 3.156 on 48 degrees of freedom
#> Multiple R-squared: 0.6511, Adjusted R-squared: 0.6438
#> F-statistic: 89.57 on 1 and 48 DF, p-value: 1.49e-12
lmtest::coeftest(model, vcov. = sandwich::vcovHC(model, type = "HC1"))
#>
#> t test of coefficients:
#>
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 8.283906 0.891860 9.2883 2.682e-12 ***
#> dist 0.165568 0.019402 8.5335 3.482e-11 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 140.4.6 Model to Equation
Use equatiomatic to extract LaTeX-ready equations. If unavailable, we provide a fallback to print the fitted equation with estimated coefficients.
# install.packages("equatiomatic") # not available for some R versions (e.g., R 4.2)
fit_eq <- lm(metascore ~ log1p(budget) + log1p(us_gross) + runtime + year, data = movies_small)
# Show the theoretical model
equatiomatic::extract_eq(fit_eq)
# Display the actual coefficients
equatiomatic::extract_eq(fit_eq, use_coefs = TRUE)
# Fallback: build a simple equation string with estimated coefs
print_lm_equation <- function(mod) {
co <- coef(mod)
terms <- names(co)
terms_fmt <- ifelse(terms == "(Intercept)",
sprintf("%.3f", co[terms]),
paste0(sprintf("%.3f", co[terms]), " \\cdot ", terms))
rhs <- paste(terms_fmt, collapse = " + ")
asis <- paste0("$\\hat{y} = ", rhs, "$")
cat(asis, "\n")
}
print_lm_equation(fit)
#> $\hat{y} = 108.910 + -6.669 \cdot log1p(budget) + 3.804 \cdot log1p(us_gross) + 14.269 \cdot runtime + -0.013 \cdot year$40.5 Model Comparison
Compare nested models via ANOVA (F-test), and non-nested via AIC/BIC, cross-validation, or predictive performance metrics. jtools::export_summs() offers attractive comparison tables.
fit_a <- lm(metascore ~ log1p(budget), data = movies_small)
fit_b <- lm(metascore ~ log1p(budget) + log1p(us_gross), data = movies_small)
fit_c <- lm(metascore ~ log1p(budget) + log1p(us_gross) + runtime, data = movies_small)
coef_names <- c("Budget" = "log1p(budget)",
"US Gross" = "log1p(us_gross)",
"Runtime (Hours)" = "runtime",
"Constant" = "(Intercept)")
export_summs(fit_a, fit_b, fit_c, robust = "HC3", coefs = coef_names)| Model 1 | Model 2 | Model 3 | |
|---|---|---|---|
| Budget | -2.43 *** | -5.16 *** | -6.70 *** |
| (0.44) | (0.62) | (0.67) | |
| US Gross | 3.96 *** | 3.85 *** | |
| (0.51) | (0.48) | ||
| Runtime (Hours) | 14.29 *** | ||
| (1.63) | |||
| Constant | 105.29 *** | 81.84 *** | 83.35 *** |
| (7.65) | (8.66) | (8.82) | |
| N | 831 | 831 | 831 |
| R2 | 0.03 | 0.09 | 0.17 |
| Standard errors are heteroskedasticity robust. *** p < 0.001; ** p < 0.01; * p < 0.05. | |||
# AIC/BIC comparison
broom::glance(fit_a) %>% select(AIC, BIC, adj.r.squared) %>% mutate(model = "fit_a")
#> # A tibble: 1 × 4
#> AIC BIC adj.r.squared model
#> <dbl> <dbl> <dbl> <chr>
#> 1 7039. 7053. 0.0271 fit_a
broom::glance(fit_b) %>% select(AIC, BIC, adj.r.squared) %>% mutate(model = "fit_b")
#> # A tibble: 1 × 4
#> AIC BIC adj.r.squared model
#> <dbl> <dbl> <dbl> <chr>
#> 1 6984. 7003. 0.0910 fit_b
broom::glance(fit_c) %>% select(AIC, BIC, adj.r.squared) %>% mutate(model = "fit_c")
#> # A tibble: 1 × 4
#> AIC BIC adj.r.squared model
#> <dbl> <dbl> <dbl> <chr>
#> 1 6913. 6937. 0.166 fit_c
# Nested model ANOVA (fit_a ⊂ fit_b ⊂ fit_c)
anova(fit_a, fit_b, fit_c)
#> Analysis of Variance Table
#>
#> Model 1: metascore ~ log1p(budget)
#> Model 2: metascore ~ log1p(budget) + log1p(us_gross)
#> Model 3: metascore ~ log1p(budget) + log1p(us_gross) + runtime
#> Res.Df RSS Df Sum of Sq F Pr(>F)
#> 1 829 230545
#> 2 828 215136 1 15409 64.634 3.11e-15 ***
#> 3 827 197160 1 17976 75.401 < 2.2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 140.6 Changes in an Estimate
Visualize how coefficient estimates shift when adding controls. This is especially useful to show robustness to omitted variable bias concerns.
coef_names_plot <- coef_names[1:3] # Dropping intercept for plots
plot_summs(fit_a, fit_b, fit_c, robust = "HC3", coefs = coef_names_plot)
plot_summs(
fit_c,
robust = "HC3",
coefs = coef_names_plot,
plot.distributions = TRUE
)
40.6.1 Coefficient Uncertainty and Distribution
Visualize uncertainty with either frequentist or Bayesian approaches. With frequentist OLS, we can simulate coefficient draws from the asymptotic sampling distribution using the estimated variance-covariance matrix and then plot with ggplot2.
# Simulate coefficient draws (multivariate normal approx)
if (requireNamespace("MASS", quietly = TRUE)) {
V <- vcovHC(fit_c, type = "HC3")
b <- coef(fit_c)
draws <- MASS::mvrnorm(n = 5000, mu = b, Sigma = V)
draws_df <- as.data.frame(draws) %>%
select(`log1p(budget)`, `log1p(us_gross)`, runtime)
draws_long <- tidyr::pivot_longer(draws_df, everything(), names_to = "term", values_to = "beta")
ggplot(draws_long, aes(beta)) +
facet_wrap(~ term, scales = "free") +
geom_density(fill = "#6baed6", alpha = 0.6) +
geom_vline(xintercept = 0, linetype = 2) +
labs(title = "Sampling Distributions of Selected Coefficients (HC3)",
x = "Coefficient value", y = "Density") +
theme_bw(base_size = 12)
}
40.7 Descriptive Tables
Produce journal-quality descriptives and regression tables. Below are multiple options to match target outlet styles (APA, AER, WSJ, etc.)
# Example with gtsummary: one-table overview
if (requireNamespace("gtsummary", quietly = TRUE)) {
library(gtsummary)
movies_small %>%
mutate(
across(c(budget, us_gross), log1p),
score_group = cut(metascore,
breaks = quantile(metascore, probs = c(0, .5, 1)),
include.lowest = TRUE,
labels = c("Low score", "High score"))
) %>%
select(metascore, budget, us_gross, runtime, year, score_group) %>%
tbl_summary(
by = score_group,
statistic = list(all_continuous() ~ "{mean} ({sd})"),
digits = all_continuous() ~ 1
) %>%
add_overall() %>%
add_p() %>%
bold_labels()
}| Characteristic |
Overall N = 8311 |
Low score N = 4311 |
High score N = 4001 |
p-value2 |
|---|---|---|---|---|
| metascore | 63.0 (16.9) | 50.0 (11.3) | 77.1 (8.7) | <0.001 |
| budget | 17.4 (1.2) | 17.7 (0.9) | 17.2 (1.3) | <0.001 |
| us_gross | 17.9 (1.4) | 17.9 (1.2) | 18.0 (1.5) | 0.3 |
| runtime | 1.9 (0.4) | 1.9 (0.3) | 2.0 (0.4) | 0.004 |
| year | 2,002.2 (9.0) | 2,003.0 (8.0) | 2,001.3 (9.9) | 0.056 |
| 1 Mean (SD) | ||||
| 2 Wilcoxon rank sum test | ||||
# modelsummary example
if (requireNamespace("modelsummary", quietly = TRUE)) {
library(modelsummary)
lm_mod <- lm(mpg ~ wt + hp + cyl, mtcars)
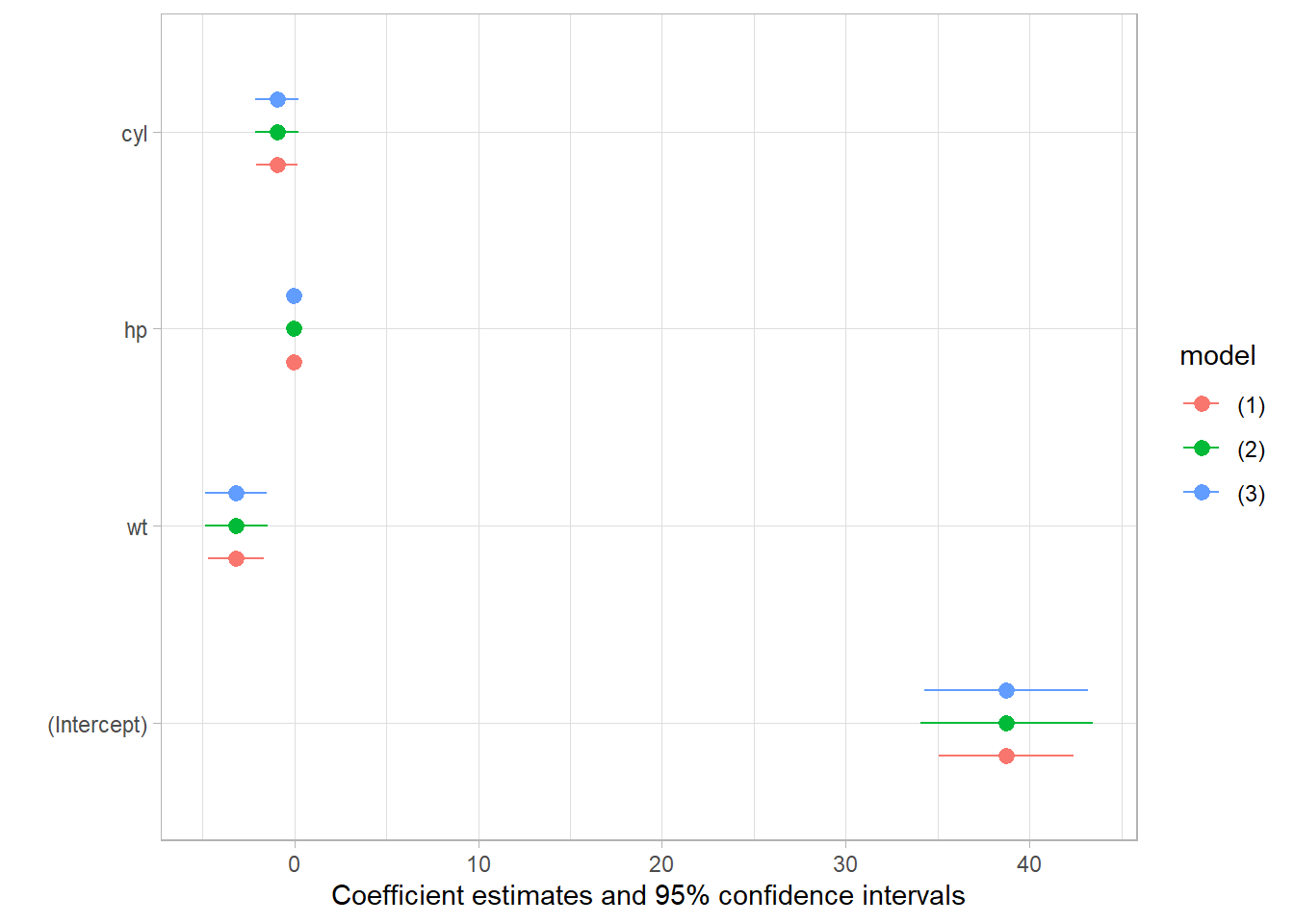
msummary(lm_mod, vcov = c("iid","robust","HC4"))
modelplot(lm_mod, vcov = c("iid","robust","HC4"))
}
# stargazer examples, including correlation and ASCII output
if (requireNamespace("stargazer", quietly = TRUE)) {
library(stargazer)
stargazer(attitude)
linear.1 <- lm(rating ~ complaints + privileges + learning + raises + critical, data = attitude)
linear.2 <- lm(rating ~ complaints + privileges + learning, data = attitude)
attitude$high.rating <- (attitude$rating > 70)
probit.model <- glm(high.rating ~ learning + critical + advance,
data = attitude,
family = binomial(link = "probit"))
stargazer(linear.1, linear.2, probit.model,
title = "Results",
align = TRUE)
# ASCII text output with CI
stargazer(
linear.1,
linear.2,
type = "text",
title = "Regression Results",
dep.var.labels = c("Overall Rating", "High Rating"),
covariate.labels = c(
"Handling of Complaints",
"No Special Privileges",
"Opportunity to Learn",
"Performance-Based Raises",
"Too Critical",
"Advancement"
),
omit.stat = c("LL", "ser", "f"),
ci = TRUE,
ci.level = 0.90,
single.row = TRUE
)
# Correlation table
correlation.matrix <- cor(attitude[, c("rating", "complaints", "privileges")])
stargazer(correlation.matrix, title = "Correlation Matrix")
}
#>
#> % Table created by stargazer v.5.2.3 by Marek Hlavac, Social Policy Institute. E-mail: marek.hlavac at gmail.com
#> % Date and time: Mon, Nov 03, 2025 - 8:30:37 PM
#> \begin{table}[!htbp] \centering
#> \caption{}
#> \label{}
#> \begin{tabular}{@{\extracolsep{5pt}}lccccc}
#> \\[-1.8ex]\hline
#> \hline \\[-1.8ex]
#> Statistic & \multicolumn{1}{c}{N} & \multicolumn{1}{c}{Mean} & \multicolumn{1}{c}{St. Dev.} & \multicolumn{1}{c}{Min} & \multicolumn{1}{c}{Max} \\
#> \hline \\[-1.8ex]
#> rating & 30 & 64.633 & 12.173 & 40 & 85 \\
#> complaints & 30 & 66.600 & 13.315 & 37 & 90 \\
#> privileges & 30 & 53.133 & 12.235 & 30 & 83 \\
#> learning & 30 & 56.367 & 11.737 & 34 & 75 \\
#> raises & 30 & 64.633 & 10.397 & 43 & 88 \\
#> critical & 30 & 74.767 & 9.895 & 49 & 92 \\
#> advance & 30 & 42.933 & 10.289 & 25 & 72 \\
#> \hline \\[-1.8ex]
#> \end{tabular}
#> \end{table}
#>
#> % Table created by stargazer v.5.2.3 by Marek Hlavac, Social Policy Institute. E-mail: marek.hlavac at gmail.com
#> % Date and time: Mon, Nov 03, 2025 - 8:30:37 PM
#> % Requires LaTeX packages: dcolumn
#> \begin{table}[!htbp] \centering
#> \caption{Results}
#> \label{}
#> \begin{tabular}{@{\extracolsep{5pt}}lD{.}{.}{-3} D{.}{.}{-3} D{.}{.}{-3} }
#> \\[-1.8ex]\hline
#> \hline \\[-1.8ex]
#> & \multicolumn{3}{c}{\textit{Dependent variable:}} \\
#> \cline{2-4}
#> \\[-1.8ex] & \multicolumn{2}{c}{rating} & \multicolumn{1}{c}{high.rating} \\
#> \\[-1.8ex] & \multicolumn{2}{c}{\textit{OLS}} & \multicolumn{1}{c}{\textit{probit}} \\
#> \\[-1.8ex] & \multicolumn{1}{c}{(1)} & \multicolumn{1}{c}{(2)} & \multicolumn{1}{c}{(3)}\\
#> \hline \\[-1.8ex]
#> complaints & 0.692^{***} & 0.682^{***} & \\
#> & (0.149) & (0.129) & \\
#> & & & \\
#> privileges & -0.104 & -0.103 & \\
#> & (0.135) & (0.129) & \\
#> & & & \\
#> learning & 0.249 & 0.238^{*} & 0.164^{***} \\
#> & (0.160) & (0.139) & (0.053) \\
#> & & & \\
#> raises & -0.033 & & \\
#> & (0.202) & & \\
#> & & & \\
#> critical & 0.015 & & -0.001 \\
#> & (0.147) & & (0.044) \\
#> & & & \\
#> advance & & & -0.062 \\
#> & & & (0.042) \\
#> & & & \\
#> Constant & 11.011 & 11.258 & -7.476^{**} \\
#> & (11.704) & (7.318) & (3.570) \\
#> & & & \\
#> \hline \\[-1.8ex]
#> Observations & \multicolumn{1}{c}{30} & \multicolumn{1}{c}{30} & \multicolumn{1}{c}{30} \\
#> R$^{2}$ & \multicolumn{1}{c}{0.715} & \multicolumn{1}{c}{0.715} & \\
#> Adjusted R$^{2}$ & \multicolumn{1}{c}{0.656} & \multicolumn{1}{c}{0.682} & \\
#> Log Likelihood & & & \multicolumn{1}{c}{-9.087} \\
#> Akaike Inf. Crit. & & & \multicolumn{1}{c}{26.175} \\
#> Residual Std. Error & \multicolumn{1}{c}{7.139 (df = 24)} & \multicolumn{1}{c}{6.863 (df = 26)} & \\
#> F Statistic & \multicolumn{1}{c}{12.063$^{***}$ (df = 5; 24)} & \multicolumn{1}{c}{21.743$^{***}$ (df = 3; 26)} & \\
#> \hline
#> \hline \\[-1.8ex]
#> \textit{Note:} & \multicolumn{3}{r}{$^{*}$p$<$0.1; $^{**}$p$<$0.05; $^{***}$p$<$0.01} \\
#> \end{tabular}
#> \end{table}
#>
#> Regression Results
#> ========================================================================
#> Dependent variable:
#> -----------------------------------------------
#> Overall Rating
#> (1) (2)
#> ------------------------------------------------------------------------
#> Handling of Complaints 0.692*** (0.447, 0.937) 0.682*** (0.470, 0.894)
#> No Special Privileges -0.104 (-0.325, 0.118) -0.103 (-0.316, 0.109)
#> Opportunity to Learn 0.249 (-0.013, 0.512) 0.238* (0.009, 0.467)
#> Performance-Based Raises -0.033 (-0.366, 0.299)
#> Too Critical 0.015 (-0.227, 0.258)
#> Advancement 11.011 (-8.240, 30.262) 11.258 (-0.779, 23.296)
#> ------------------------------------------------------------------------
#> Observations 30 30
#> R2 0.715 0.715
#> Adjusted R2 0.656 0.682
#> ========================================================================
#> Note: *p<0.1; **p<0.05; ***p<0.01
#>
#> % Table created by stargazer v.5.2.3 by Marek Hlavac, Social Policy Institute. E-mail: marek.hlavac at gmail.com
#> % Date and time: Mon, Nov 03, 2025 - 8:30:37 PM
#> \begin{table}[!htbp] \centering
#> \caption{Correlation Matrix}
#> \label{}
#> \begin{tabular}{@{\extracolsep{5pt}} cccc}
#> \\[-1.8ex]\hline
#> \hline \\[-1.8ex]
#> & rating & complaints & privileges \\
#> \hline \\[-1.8ex]
#> rating & $1$ & $0.825$ & $0.426$ \\
#> complaints & $0.825$ & $1$ & $0.558$ \\
#> privileges & $0.426$ & $0.558$ & $1$ \\
#> \hline \\[-1.8ex]
#> \end{tabular}
#> \end{table}
# LaTeX output (uncomment to use)
stargazer(
linear.1,
linear.2,
probit.model,
title = "Regression Results",
align = TRUE,
dep.var.labels = c("Overall Rating", "High Rating"),
covariate.labels = c(
"Handling of Complaints",
"No Special Privileges",
"Opportunity to Learn",
"Performance-Based Raises",
"Too Critical",
"Advancement"
),
omit.stat = c("LL", "ser", "f"),
no.space = TRUE
)40.7.1 Export APA theme (flextable)
Below creates an APA-like table for a subset of mtcars.
You can export data frames to LaTeX via xtable and ready-made styles via stargazer. (Ensure output directory exists.)
print(xtable::xtable(mtcars, type = "latex"),
file = file.path(getwd(), "output", "mtcars_xtable.tex"))
# American Economic Review style
stargazer::stargazer(
mtcars,
title = "Testing",
style = "aer",
out = file.path(getwd(), "output", "mtcars_stargazer.tex")
)However, some exporters don’t play well with table notes. Below is a custom function following AMA-style notes placement.
ama_tbl <- function(data, caption, label, note, output_path) {
library(tidyverse)
library(xtable)
# Function to determine column alignment
get_column_alignment <- function(data) {
# xtable align requires length ncol + 1; first is for rownames
alignment <- c("l", "l")
for (col in seq_len(ncol(data))[-1]) {
if (is.numeric(data[[col]])) {
alignment <- c(alignment, "r")
} else {
alignment <- c(alignment, "c")
}
}
alignment
}
data %>%
# bold + left align first column
rename_with(~paste0("\\\\multicolumn{1}{l}{\\\\textbf{", ., "}}"), 1) %>%
# bold + center align all other columns
`colnames<-`(ifelse(colnames(.) != colnames(.)[1],
paste0("\\\\multicolumn{1}{c}{\\\\textbf{", colnames(.), "}}"),
colnames(.))) %>%
xtable(caption = caption,
label = label,
align = get_column_alignment(data),
auto = TRUE) %>%
print(
include.rownames = FALSE,
caption.placement = "top",
hline.after = c(-1, 0),
add.to.row = list(
pos = list(nrow(data)),
command = c(
paste0("\\\\hline \n \\\\multicolumn{", ncol(data),
"}{l}{ \n \\\\begin{tabular}{@{}p{0.9\\\\linewidth}@{}} \n",
"Note: ", note, "\n \\\\end{tabular} } \n")
)
),
sanitize.colnames.function = identity,
table.placement = "h",
file = output_path
)
}40.8 Visualizations & Plots
Customize plots to match target journal aesthetics. Below we provide an American Marketing Association–ready theme and examples. (Change fonts on your system as needed.)
# AMA-inspired theme (serif base, clean grid)
amatheme <- theme_bw(base_size = 14, base_family = "serif") +
theme(
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.border = element_blank(),
line = element_line(),
text = element_text(),
legend.title = element_text(size = rel(0.6), face = "bold"),
legend.text = element_text(size = rel(0.6)),
legend.background = element_rect(color = "black"),
plot.title = element_text(
size = rel(1.2),
face = "bold",
hjust = 0.5,
margin = margin(b = 15)
),
plot.margin = unit(c(1, 1, 1, 1), "cm"),
axis.line = element_line(colour = "black", linewidth = .8),
axis.ticks = element_line(),
axis.title.x = element_text(size = rel(1.2), face = "bold"),
axis.title.y = element_text(size = rel(1.2), face = "bold"),
axis.text.y = element_text(size = rel(1)),
axis.text.x = element_text(size = rel(1))
)
# Example plot
library(tidyverse)
library(ggsci)
data("mtcars")
yourplot <- mtcars %>%
select(mpg, cyl, gear) %>%
ggplot(aes(x = mpg, y = cyl, color = factor(gear))) +
geom_point(size = 2, alpha = .8) +
labs(title = "Example Plot", x = "MPG", y = "Cylinders", color = "Gears")
yourplot + amatheme + scale_color_npg()
yourplot + amatheme + scale_color_viridis_d()
# Other pre-specified themes
library(ggthemes)
yourplot + theme_stata()
yourplot + theme_economist()
yourplot + theme_economist_white()
yourplot + theme_wsj()
# APA-like theme from jtools
jtools::theme_apa(
legend.font.size = 12,
x.font.size = 12,
y.font.size = 12
)
#> <theme> List of 144
#> $ line : <ggplot2::element_line>
#> ..@ colour : chr "black"
#> ..@ linewidth : num 0.5
#> ..@ linetype : num 1
#> ..@ lineend : chr "butt"
#> ..@ linejoin : chr "round"
#> ..@ arrow : logi FALSE
#> ..@ arrow.fill : chr "black"
#> ..@ inherit.blank: logi TRUE
#> $ rect : <ggplot2::element_rect>
#> ..@ fill : chr "white"
#> ..@ colour : chr "black"
#> ..@ linewidth : num 0.5
#> ..@ linetype : num 1
#> ..@ linejoin : chr "round"
#> ..@ inherit.blank: logi TRUE
#> $ text : <ggplot2::element_text>
#> ..@ family : chr ""
#> ..@ face : chr "plain"
#> ..@ italic : chr NA
#> ..@ fontweight : num NA
#> ..@ fontwidth : num NA
#> ..@ colour : chr "black"
#> ..@ size : num 11
#> ..@ hjust : num 0.5
#> ..@ vjust : num 0.5
#> ..@ angle : num 0
#> ..@ lineheight : num 0.9
#> ..@ margin : <ggplot2::margin> num [1:4] 0 0 0 0
#> ..@ debug : logi FALSE
#> ..@ inherit.blank: logi TRUE
#> $ title : <ggplot2::element_text>
#> ..@ family : NULL
#> ..@ face : NULL
#> ..@ italic : chr NA
#> ..@ fontweight : num NA
#> ..@ fontwidth : num NA
#> ..@ colour : NULL
#> ..@ size : NULL
#> ..@ hjust : NULL
#> ..@ vjust : NULL
#> ..@ angle : NULL
#> ..@ lineheight : NULL
#> ..@ margin : NULL
#> ..@ debug : NULL
#> ..@ inherit.blank: logi TRUE
#> $ point : <ggplot2::element_point>
#> ..@ colour : chr "black"
#> ..@ shape : num 19
#> ..@ size : num 1.5
#> ..@ fill : chr "white"
#> ..@ stroke : num 0.5
#> ..@ inherit.blank: logi TRUE
#> $ polygon : <ggplot2::element_polygon>
#> ..@ fill : chr "white"
#> ..@ colour : chr "black"
#> ..@ linewidth : num 0.5
#> ..@ linetype : num 1
#> ..@ linejoin : chr "round"
#> ..@ inherit.blank: logi TRUE
#> $ geom : <ggplot2::element_geom>
#> ..@ ink : chr "black"
#> ..@ paper : chr "white"
#> ..@ accent : chr "#3366FF"
#> ..@ linewidth : num 0.5
#> ..@ borderwidth: num 0.5
#> ..@ linetype : int 1
#> ..@ bordertype : int 1
#> ..@ family : chr ""
#> ..@ fontsize : num 3.87
#> ..@ pointsize : num 1.5
#> ..@ pointshape : num 19
#> ..@ colour : NULL
#> ..@ fill : NULL
#> $ spacing : 'simpleUnit' num 5.5points
#> ..- attr(*, "unit")= int 8
#> $ margins : <ggplot2::margin> num [1:4] 5.5 5.5 5.5 5.5
#> $ aspect.ratio : NULL
#> $ axis.title : NULL
#> $ axis.title.x : <ggplot2::element_text>
#> ..@ family : NULL
#> ..@ face : NULL
#> ..@ italic : chr NA
#> ..@ fontweight : num NA
#> ..@ fontwidth : num NA
#> ..@ colour : NULL
#> ..@ size : num 12
#> ..@ hjust : NULL
#> ..@ vjust : num 1
#> ..@ angle : NULL
#> ..@ lineheight : NULL
#> ..@ margin : <ggplot2::margin> num [1:4] 2.75 0 0 0
#> ..@ debug : NULL
#> ..@ inherit.blank: logi FALSE
#> $ axis.title.x.top : <ggplot2::element_text>
#> ..@ family : NULL
#> ..@ face : NULL
#> ..@ italic : chr NA
#> ..@ fontweight : num NA
#> ..@ fontwidth : num NA
#> ..@ colour : NULL
#> ..@ size : NULL
#> ..@ hjust : NULL
#> ..@ vjust : num 0
#> ..@ angle : NULL
#> ..@ lineheight : NULL
#> ..@ margin : <ggplot2::margin> num [1:4] 0 0 2.75 0
#> ..@ debug : NULL
#> ..@ inherit.blank: logi TRUE
#> $ axis.title.x.bottom : NULL
#> $ axis.title.y : <ggplot2::element_text>
#> ..@ family : NULL
#> ..@ face : NULL
#> ..@ italic : chr NA
#> ..@ fontweight : num NA
#> ..@ fontwidth : num NA
#> ..@ colour : NULL
#> ..@ size : num 12
#> ..@ hjust : NULL
#> ..@ vjust : num 1
#> ..@ angle : num 90
#> ..@ lineheight : NULL
#> ..@ margin : <ggplot2::margin> num [1:4] 0 2.75 0 0
#> ..@ debug : NULL
#> ..@ inherit.blank: logi FALSE
#> $ axis.title.y.left : NULL
#> $ axis.title.y.right : <ggplot2::element_text>
#> ..@ family : NULL
#> ..@ face : NULL
#> ..@ italic : chr NA
#> ..@ fontweight : num NA
#> ..@ fontwidth : num NA
#> ..@ colour : NULL
#> ..@ size : NULL
#> ..@ hjust : NULL
#> ..@ vjust : num 1
#> ..@ angle : num -90
#> ..@ lineheight : NULL
#> ..@ margin : <ggplot2::margin> num [1:4] 0 0 0 2.75
#> ..@ debug : NULL
#> ..@ inherit.blank: logi TRUE
#> $ axis.text : <ggplot2::element_text>
#> ..@ family : NULL
#> ..@ face : NULL
#> ..@ italic : chr NA
#> ..@ fontweight : num NA
#> ..@ fontwidth : num NA
#> ..@ colour : chr "#4D4D4DFF"
#> ..@ size : 'rel' num 0.8
#> ..@ hjust : NULL
#> ..@ vjust : NULL
#> ..@ angle : NULL
#> ..@ lineheight : NULL
#> ..@ margin : NULL
#> ..@ debug : NULL
#> ..@ inherit.blank: logi TRUE
#> $ axis.text.x : <ggplot2::element_text>
#> ..@ family : NULL
#> ..@ face : NULL
#> ..@ italic : chr NA
#> ..@ fontweight : num NA
#> ..@ fontwidth : num NA
#> ..@ colour : NULL
#> ..@ size : NULL
#> ..@ hjust : NULL
#> ..@ vjust : num 1
#> ..@ angle : NULL
#> ..@ lineheight : NULL
#> ..@ margin : <ggplot2::margin> num [1:4] 2.2 0 0 0
#> ..@ debug : NULL
#> ..@ inherit.blank: logi TRUE
#> $ axis.text.x.top : <ggplot2::element_text>
#> ..@ family : NULL
#> ..@ face : NULL
#> ..@ italic : chr NA
#> ..@ fontweight : num NA
#> ..@ fontwidth : num NA
#> ..@ colour : NULL
#> ..@ size : NULL
#> ..@ hjust : NULL
#> ..@ vjust : num 0
#> ..@ angle : NULL
#> ..@ lineheight : NULL
#> ..@ margin : <ggplot2::margin> num [1:4] 0 0 2.2 0
#> ..@ debug : NULL
#> ..@ inherit.blank: logi TRUE
#> $ axis.text.x.bottom : NULL
#> $ axis.text.y : <ggplot2::element_text>
#> ..@ family : NULL
#> ..@ face : NULL
#> ..@ italic : chr NA
#> ..@ fontweight : num NA
#> ..@ fontwidth : num NA
#> ..@ colour : NULL
#> ..@ size : NULL
#> ..@ hjust : num 1
#> ..@ vjust : NULL
#> ..@ angle : NULL
#> ..@ lineheight : NULL
#> ..@ margin : <ggplot2::margin> num [1:4] 0 2.2 0 0
#> ..@ debug : NULL
#> ..@ inherit.blank: logi TRUE
#> $ axis.text.y.left : NULL
#> $ axis.text.y.right : <ggplot2::element_text>
#> ..@ family : NULL
#> ..@ face : NULL
#> ..@ italic : chr NA
#> ..@ fontweight : num NA
#> ..@ fontwidth : num NA
#> ..@ colour : NULL
#> ..@ size : NULL
#> ..@ hjust : num 0
#> ..@ vjust : NULL
#> ..@ angle : NULL
#> ..@ lineheight : NULL
#> ..@ margin : <ggplot2::margin> num [1:4] 0 0 0 2.2
#> ..@ debug : NULL
#> ..@ inherit.blank: logi TRUE
#> $ axis.text.theta : NULL
#> $ axis.text.r : <ggplot2::element_text>
#> ..@ family : NULL
#> ..@ face : NULL
#> ..@ italic : chr NA
#> ..@ fontweight : num NA
#> ..@ fontwidth : num NA
#> ..@ colour : NULL
#> ..@ size : NULL
#> ..@ hjust : num 0.5
#> ..@ vjust : NULL
#> ..@ angle : NULL
#> ..@ lineheight : NULL
#> ..@ margin : <ggplot2::margin> num [1:4] 0 2.2 0 2.2
#> ..@ debug : NULL
#> ..@ inherit.blank: logi TRUE
#> $ axis.ticks : <ggplot2::element_line>
#> ..@ colour : chr "#333333FF"
#> ..@ linewidth : NULL
#> ..@ linetype : NULL
#> ..@ lineend : NULL
#> ..@ linejoin : NULL
#> ..@ arrow : logi FALSE
#> ..@ arrow.fill : chr "#333333FF"
#> ..@ inherit.blank: logi TRUE
#> $ axis.ticks.x : NULL
#> $ axis.ticks.x.top : NULL
#> $ axis.ticks.x.bottom : NULL
#> $ axis.ticks.y : NULL
#> $ axis.ticks.y.left : NULL
#> $ axis.ticks.y.right : NULL
#> $ axis.ticks.theta : NULL
#> $ axis.ticks.r : NULL
#> $ axis.minor.ticks.x.top : NULL
#> $ axis.minor.ticks.x.bottom : NULL
#> $ axis.minor.ticks.y.left : NULL
#> $ axis.minor.ticks.y.right : NULL
#> $ axis.minor.ticks.theta : NULL
#> $ axis.minor.ticks.r : NULL
#> $ axis.ticks.length : 'rel' num 0.5
#> $ axis.ticks.length.x : NULL
#> $ axis.ticks.length.x.top : NULL
#> $ axis.ticks.length.x.bottom : NULL
#> $ axis.ticks.length.y : NULL
#> $ axis.ticks.length.y.left : NULL
#> $ axis.ticks.length.y.right : NULL
#> $ axis.ticks.length.theta : NULL
#> $ axis.ticks.length.r : NULL
#> $ axis.minor.ticks.length : 'rel' num 0.75
#> $ axis.minor.ticks.length.x : NULL
#> $ axis.minor.ticks.length.x.top : NULL
#> $ axis.minor.ticks.length.x.bottom: NULL
#> $ axis.minor.ticks.length.y : NULL
#> $ axis.minor.ticks.length.y.left : NULL
#> $ axis.minor.ticks.length.y.right : NULL
#> $ axis.minor.ticks.length.theta : NULL
#> $ axis.minor.ticks.length.r : NULL
#> $ axis.line : <ggplot2::element_blank>
#> $ axis.line.x : NULL
#> $ axis.line.x.top : NULL
#> $ axis.line.x.bottom : NULL
#> $ axis.line.y : NULL
#> $ axis.line.y.left : NULL
#> $ axis.line.y.right : NULL
#> $ axis.line.theta : NULL
#> $ axis.line.r : NULL
#> $ legend.background : <ggplot2::element_rect>
#> ..@ fill : NULL
#> ..@ colour : logi NA
#> ..@ linewidth : NULL
#> ..@ linetype : NULL
#> ..@ linejoin : NULL
#> ..@ inherit.blank: logi TRUE
#> $ legend.margin : NULL
#> $ legend.spacing : 'rel' num 2
#> $ legend.spacing.x : NULL
#> $ legend.spacing.y : NULL
#> $ legend.key : <ggplot2::element_blank>
#> $ legend.key.size : 'simpleUnit' num 1.5lines
#> ..- attr(*, "unit")= int 3
#> $ legend.key.height : NULL
#> $ legend.key.width : 'simpleUnit' num 2lines
#> ..- attr(*, "unit")= int 3
#> $ legend.key.spacing : NULL
#> $ legend.key.spacing.x : NULL
#> $ legend.key.spacing.y : NULL
#> $ legend.key.justification : NULL
#> $ legend.frame : NULL
#> $ legend.ticks : NULL
#> $ legend.ticks.length : 'rel' num 0.2
#> $ legend.axis.line : NULL
#> $ legend.text : <ggplot2::element_text>
#> ..@ family : NULL
#> ..@ face : NULL
#> ..@ italic : chr NA
#> ..@ fontweight : num NA
#> ..@ fontwidth : num NA
#> ..@ colour : NULL
#> ..@ size : num 12
#> ..@ hjust : NULL
#> ..@ vjust : NULL
#> ..@ angle : NULL
#> ..@ lineheight : NULL
#> ..@ margin : NULL
#> ..@ debug : NULL
#> ..@ inherit.blank: logi FALSE
#> $ legend.text.position : NULL
#> $ legend.title : <ggplot2::element_blank>
#> $ legend.title.position : NULL
#> $ legend.position : chr "right"
#> $ legend.position.inside : NULL
#> $ legend.direction : NULL
#> $ legend.byrow : NULL
#> $ legend.justification : chr "center"
#> $ legend.justification.top : NULL
#> $ legend.justification.bottom : NULL
#> $ legend.justification.left : NULL
#> $ legend.justification.right : NULL
#> $ legend.justification.inside : NULL
#> [list output truncated]
#> @ complete: logi TRUE
#> @ validate: logi TRUE
yourplot + jtools::theme_apa()
40.9 One-Table Summary
A pragmatic approach for business audiences: show descriptives and key regression side-by-side (or sequentially) in a single, coherent section. This can be achieved with gtsummary::tbl_merge() combining tbl_summary() and tbl_regression().
if (requireNamespace("gtsummary", quietly = TRUE) &&
requireNamespace("gt", quietly = TRUE)) {
library(gtsummary)
library(gt)
mod_for_tbl <- lm(metascore ~ log1p(budget) + log1p(us_gross) + runtime + year, data = movies_small)
tbl1 <- movies_small %>%
mutate(across(c(budget, us_gross), log1p)) %>%
select(metascore, budget, us_gross, runtime, year) %>%
tbl_summary(
statistic = all_continuous() ~ "{mean} ({sd})",
digits = all_continuous() ~ 1
) %>%
bold_labels()
tbl2 <- tbl_regression(mod_for_tbl, exponentiate = FALSE) %>%
add_glance_table(include = c(r.squared, adj.r.squared, AIC, BIC), label = list(r.squared ~ "R^2",
adj.r.squared ~ "Adj. R^2"))
tbl_merge(
tbls = list(tbl1, tbl2),
tab_spanner = c("**Descriptive Statistics**", "**Regression Results**")
) %>%
as_gt() %>%
tab_source_note(source_note = md("SEs are HC3-robust unless otherwise noted."))
}| Characteristic |
Descriptive Statistics
|
Regression Results
|
||
|---|---|---|---|---|
| N = 8311 | Beta | 95% CI | p-value | |
| metascore | 63.0 (16.9) | |||
| budget | 17.4 (1.2) | |||
| us_gross | 17.9 (1.4) | |||
| runtime | 1.9 (0.4) | 14 | 11, 18 | <0.001 |
| year | 2,002.2 (9.0) | -0.01 | -0.14, 0.12 | 0.8 |
| log1p(budget) | -6.7 | -7.9, -5.5 | <0.001 | |
| log1p(us_gross) | 3.8 | 2.7, 4.9 | <0.001 | |
| R^2 | 0.169 | |||
| Adj. R^2 | 0.165 | |||
| AIC | 6,915 | |||
| BIC | 6,943 | |||
| 1 Mean (SD) | ||||
| Abbreviation: CI = Confidence Interval | ||||
| SEs are HC3-robust unless otherwise noted. | ||||
40.10 Inference / Prediction
Beyond classical t-tests:
Bootstrap CIs (resample rows)
Permutation tests (randomize treatment/feature under \(H_0\))
Cross-validation for predictive accuracy (RMSE/MAE)
Prediction intervals for new observations
# Bootstrap coefficient CIs (percentile) using boot
if (requireNamespace("boot", quietly = TRUE)) {
library(boot)
boot_fun <- function(data, idx) {
m <- lm(metascore ~ log1p(budget) + log1p(us_gross) + runtime + year, data = data[idx, , drop = FALSE])
coef(m)
}
bt <- boot(movies_small, statistic = boot_fun, R = 1000)
# Percentile CI for log1p(budget)
boot.ci(bt, type = "perc", index = which(names(coef(fit)) == "log1p(budget)"))
}
#> BOOTSTRAP CONFIDENCE INTERVAL CALCULATIONS
#> Based on 1000 bootstrap replicates
#>
#> CALL :
#> boot.ci(boot.out = bt, type = "perc", index = which(names(coef(fit)) ==
#> "log1p(budget)"))
#>
#> Intervals :
#> Level Percentile
#> 95% (-8.158, -5.443 )
#> Calculations and Intervals on Original Scale
# Simple K-fold CV (caret) for RMSE
if (requireNamespace("caret", quietly = TRUE)) {
library(caret)
ctrl <- trainControl(method = "cv", number = 5)
cv_fit <- train(
metascore ~ log1p(budget) + log1p(us_gross) + runtime + year,
data = movies_small,
method = "lm",
trControl = ctrl
)
cv_fit
}
#> Linear Regression
#>
#> 831 samples
#> 4 predictor
#>
#> No pre-processing
#> Resampling: Cross-Validated (5 fold)
#> Summary of sample sizes: 665, 664, 665, 666, 664
#> Resampling results:
#>
#> RMSE Rsquared MAE
#> 15.46842 0.1624431 12.53269
#>
#> Tuning parameter 'intercept' was held constant at a value of TRUE
# Prediction intervals for new data
newdat <- tibble(
budget = median(movies_small$budget, na.rm = TRUE),
us_gross = median(movies_small$us_gross, na.rm = TRUE),
runtime = median(movies_small$runtime, na.rm = TRUE),
year = median(movies_small$year, na.rm = TRUE)
)
predict(fit, newdata = newdat, interval = "prediction", level = 0.95)
#> fit lwr upr
#> 1 62.00795 31.66255 92.3533640.11 Appendix: Reproducible Snippets
# jtools: baseline summary again for traceability
data(movies)
fit <- lm(metascore ~ budget + us_gross + year, data = movies)
summ(fit)| Observations | 831 (10 missing obs. deleted) |
| Dependent variable | metascore |
| Type | OLS linear regression |
| F(3,827) | 26.23 |
| R² | 0.09 |
| Adj. R² | 0.08 |
| Est. | S.E. | t val. | p | |
|---|---|---|---|---|
| (Intercept) | 52.06 | 139.67 | 0.37 | 0.71 |
| budget | -0.00 | 0.00 | -5.89 | 0.00 |
| us_gross | 0.00 | 0.00 | 7.61 | 0.00 |
| year | 0.01 | 0.07 | 0.08 | 0.94 |
| Standard errors: OLS |
summ(
fit,
scale = TRUE,
vifs = TRUE,
part.corr = TRUE,
confint = TRUE,
pvals = FALSE
) # notice that scale here is TRUE| Observations | 831 (10 missing obs. deleted) |
| Dependent variable | metascore |
| Type | OLS linear regression |
| F(3,827) | 26.23 |
| R² | 0.09 |
| Adj. R² | 0.08 |
| Est. | 2.5% | 97.5% | t val. | VIF | partial.r | part.r | |
|---|---|---|---|---|---|---|---|
| (Intercept) | 63.01 | 61.91 | 64.11 | 112.23 | NA | NA | NA |
| budget | -3.78 | -5.05 | -2.52 | -5.89 | 1.31 | -0.20 | -0.20 |
| us_gross | 5.28 | 3.92 | 6.64 | 7.61 | 1.52 | 0.26 | 0.25 |
| year | 0.05 | -1.18 | 1.28 | 0.08 | 1.24 | 0.00 | 0.00 |
| Standard errors: OLS; Continuous predictors are mean-centered and scaled by 1 s.d. The outcome variable remains in its original units. |
# obtain cluster-robust SE
data("PetersenCL", package = "sandwich")
fit2 <- lm(y ~ x, data = PetersenCL)
summ(fit2, robust = "HC3", cluster = "firm") | Observations | 5000 |
| Dependent variable | y |
| Type | OLS linear regression |
| F(1,4998) | 1310.74 |
| R² | 0.21 |
| Adj. R² | 0.21 |
| Est. | S.E. | t val. | p | |
|---|---|---|---|---|
| (Intercept) | 0.03 | 0.07 | 0.44 | 0.66 |
| x | 1.03 | 0.05 | 20.36 | 0.00 |
| Standard errors: Cluster-robust, type = HC3 |
# Model to Equation via equatiomatic (if available)
# install.packages("equatiomatic") # not available for R 4.2
fit <- lm(metascore ~ budget + us_gross + year, data = movies)
# show the theoretical model
equatiomatic::extract_eq(fit)
# display the actual coefficients
equatiomatic::extract_eq(fit, use_coefs = TRUE)
# Model Comparison via jtools
fit <- lm(metascore ~ log(budget), data = movies)
fit_b <- lm(metascore ~ log(budget) + log(us_gross), data = movies)
fit_c <- lm(metascore ~ log(budget) + log(us_gross) + runtime, data = movies)
coef_names <- c("Budget" = "log(budget)", "US Gross" = "log(us_gross)",
"Runtime (Hours)" = "runtime", "Constant" = "(Intercept)")
export_summs(fit, fit_b, fit_c, robust = "HC3", coefs = coef_names)| Model 1 | Model 2 | Model 3 | |
|---|---|---|---|
| Budget | -2.43 *** | -5.16 *** | -6.70 *** |
| (0.44) | (0.62) | (0.67) | |
| US Gross | 3.96 *** | 3.85 *** | |
| (0.51) | (0.48) | ||
| Runtime (Hours) | 14.29 *** | ||
| (1.63) | |||
| Constant | 105.29 *** | 81.84 *** | 83.35 *** |
| (7.65) | (8.66) | (8.82) | |
| N | 831 | 831 | 831 |
| R2 | 0.03 | 0.09 | 0.17 |
| Standard errors are heteroskedasticity robust. *** p < 0.001; ** p < 0.01; * p < 0.05. | |||
# modelsummary quick demo
library(modelsummary)
lm_mod <- lm(mpg ~ wt + hp + cyl, mtcars)
msummary(lm_mod, vcov = c("iid","robust","HC4"))| (1) | (2) | (3) | |
|---|---|---|---|
| (Intercept) | 38.752 | 38.752 | 38.752 |
| (1.787) | (2.286) | (2.177) | |
| wt | -3.167 | -3.167 | -3.167 |
| (0.741) | (0.833) | (0.819) | |
| hp | -0.018 | -0.018 | -0.018 |
| (0.012) | (0.010) | (0.013) | |
| cyl | -0.942 | -0.942 | -0.942 |
| (0.551) | (0.573) | (0.572) | |
| Num.Obs. | 32 | 32 | 32 |
| R2 | 0.843 | 0.843 | 0.843 |
| R2 Adj. | 0.826 | 0.826 | 0.826 |
| AIC | 155.5 | 155.5 | 155.5 |
| BIC | 162.8 | 162.8 | 162.8 |
| Log.Lik. | -72.738 | -72.738 | -72.738 |
| F | 50.171 | 31.065 | 32.623 |
| RMSE | 2.35 | 2.35 | 2.35 |
| Std.Errors | IID | HC3 | HC4 |

# stargazer examples (as in text)
library("stargazer")
stargazer(attitude)
linear.1 <-
lm(rating ~ complaints + privileges + learning + raises + critical,
data = attitude)
linear.2 <-
lm(rating ~ complaints + privileges + learning, data = attitude)
attitude$high.rating <- (attitude$rating > 70)
probit.model <-
glm(
high.rating ~ learning + critical + advance,
data = attitude,
family = binomial(link = "probit")
)
stargazer(linear.1,
linear.2,
probit.model,
title = "Results",
align = TRUE)
# LaTeX-ready stargazer (as in text)
stargazer(
linear.1,
linear.2,
probit.model,
title = "Regression Results",
align = TRUE,
dep.var.labels = c("Overall Rating", "High Rating"),
covariate.labels = c(
"Handling of Complaints",
"No Special Privileges",
"Opportunity to Learn",
"Performance-Based Raises",
"Too Critical",
"Advancement"
),
omit.stat = c("LL", "ser", "f"),
no.space = TRUE
)
# ASCII text output (as in text)
stargazer(
linear.1,
linear.2,
type = "text",
title = "Regression Results",
dep.var.labels = c("Overall Rating", "High Rating"),
covariate.labels = c(
"Handling of Complaints",
"No Special Privileges",
"Opportunity to Learn",
"Performance-Based Raises",
"Too Critical",
"Advancement"
),
omit.stat = c("LL", "ser", "f"),
ci = TRUE,
ci.level = 0.90,
single.row = TRUE
)
#>
#> Regression Results
#> ========================================================================
#> Dependent variable:
#> -----------------------------------------------
#> Overall Rating
#> (1) (2)
#> ------------------------------------------------------------------------
#> Handling of Complaints 0.692*** (0.447, 0.937) 0.682*** (0.470, 0.894)
#> No Special Privileges -0.104 (-0.325, 0.118) -0.103 (-0.316, 0.109)
#> Opportunity to Learn 0.249 (-0.013, 0.512) 0.238* (0.009, 0.467)
#> Performance-Based Raises -0.033 (-0.366, 0.299)
#> Too Critical 0.015 (-0.227, 0.258)
#> Advancement 11.011 (-8.240, 30.262) 11.258 (-0.779, 23.296)
#> ------------------------------------------------------------------------
#> Observations 30 30
#> R2 0.715 0.715
#> Adjusted R2 0.656 0.682
#> ========================================================================
#> Note: *p<0.1; **p<0.05; ***p<0.01
# Correlation table
correlation.matrix <-
cor(attitude[, c("rating", "complaints", "privileges")])
stargazer(correlation.matrix, title = "Correlation Matrix")Pro Tip: Save figures reproducibly for journals: