2 The key concept behind SEM: model-implied covariance matrix \(\boldsymbol{\Sigma(\theta)}\)
In the following sections within this chapter, we will illustrate the key concept of SEM by comparing SEM with conventional linear regression in a typical multiple regression scenario.
2.1 No mean structure
Because in SEM analysis, we study the relationship among variables by analyzing covariance/correlation. However, the magnitude of covariance between two given variables remains unchanged if we modified their means. We, therefore assume the means of all variables are zero, the resulting structure of interest is called no mean structure. If not this case, one can achieve zero means by centering or standardize data. This is true in most cases, (see Chapter 5 for more information). Analysis on covariance structure without considering means is often called covariance analysis.
2.2 \(\boldsymbol{\Sigma(\theta)}\)
If we are interested in the relationship between two variables, we normally use covariance/correlation (Person product-moment correlation coefficient) to quantify it. In doing so, we assume these two variables are random variables (more specifically, bivariate normally distributed).
However, in multiple regression, we have one dependent variable, and a set of predictors, \[y_i=\beta_1x_{1i}+\cdots+\beta_px_{pi}+\epsilon_i,\] where \(x_1,\ldots,x_p\) are all fixed values, that is, we treat them as variables, but not random variables. This is so called the multiple regression with fixed \(x\). The only random variables in multiple regression with fixed \(x\) are \(\boldsymbol{y}\) and \(\boldsymbol{\epsilon}\), where the randomness of \(\boldsymbol{y}\) is arguably inherited from \(\boldsymbol{\epsilon}\). Therefore, theoretically, we are not allowed to quantify the relationship among \(x\)s and \(y\) using either covariance or correlation.
But in SEM, we treat all \(x\)s and \(y\)s (yes, we can have more than 1 \(y\) in SEM) as random variables. If \(x_1\), \(\cdots\), \(x_p\) are random variables, the above model becomes multiple regression with random \(x\) (unless stated otherwise, multiple regression in this book refers to multiple regression with random \(x\)s), and now we can discuss the relationships among all variables using their covariances. The resultant covariance matrix is \[\begin{align} \Cov(x_1,\cdots,x_p,y)=\begin{bmatrix} \sigma_{x_1}^2 & \cdots & \sigma_{x_1y} \\ \vdots & & \vdots \\ \sigma_{yx_1} & \cdots & \sigma_y^2 \end{bmatrix}. \end{align}\] Because we are expressing the relationship among all variables in terms of a multiple regression model, therefore we can use the selected model to re-express the covariance matrix above, and derive a model-implied covariance matrix \(\boldsymbol{\Sigma(\theta)}\), where \(\boldsymbol{\theta}\) is a vector hosting all unknown model parameters, representing the model specified. For example, for a multiple regression with 2 predictors \(x_1\) and \(x_2\), \(\boldsymbol{\Sigma(\theta)}\) is \[\begin{align*} \begin{bmatrix} \sigma_{x_1}^2 & \sigma_{x_1x_2} & \sigma_{x_1y} \\ \sigma_{x_2x_1} & \sigma_{x_2}^2 & \sigma_{x_2y} \\ \sigma_{yx_1} & \sigma_{yx_2} & \sigma_y^2 \end{bmatrix}, \end{align*}\] where \[\begin{align*} \sigma_{x_1y}&=\Cov(x_1,\beta_1x_1+\beta_2x_2+\epsilon) \\ &=\beta_1\sigma_{x_1}^2+\beta_2\sigma_{x_1x_2}, \end{align*}\] \[\begin{align*} \sigma_{x_2y}&=\Cov(x_2,\beta_1x_1+\beta_2x_2+\epsilon) \\ &=\beta_1\sigma_{x_1x_2}+\beta_2\sigma_{x_2}^2, \end{align*}\] \[\begin{align*} \sigma_y^2&=\Cov(\beta_1x_1+\beta_2x_2+\epsilon,\beta_1x_1+\beta_2x_2+\epsilon) \\ &=\beta_1^2\sigma_{x_1}^2+\beta_2^2\sigma_{x_2}^2+2\beta_1\beta_2\sigma_{x_1x_2}+\sigma_\epsilon^2. \end{align*}\] What we have now is the model implied covariance structure of \(y=\beta_1x_1+\beta_2x_2+\epsilon\). If we assumed \(x_1\) is correlated with \(x_2\), we allow \(\sigma_{x_1,x_2}\) to be estimated freely, otherwise we can impose a restriction on it to fix it at 0.
When using sample data to estimate the specified model, we are actually trying to find the parameter estimations that satisfy the following 6 equations jointly \[\begin{align*} \begin{cases} s_{x_1}^2&=\hat{\sigma}_{x_1}^2\\ s_{x_2x_1}&=\hat{\sigma}_{x_2x_1}\\ s_{x_2}^2&=\hat{\sigma}_{x_2}^2\\ s_{yx_1}&=\hat{\beta}_1\hat{\sigma}_{x_1}^2+\hat{\beta}_2\hat{\sigma}_{x_1x_2}\\ s_{yx_2}&=\hat{\beta}_1\hat{\sigma}_{x_1x_2}+\hat{\beta}_2\hat{\sigma}_{x_2}^2\\ s_{y}^2&=\hat{\beta}_1^2\hat{\sigma}_{x_1}^2+\hat{\beta}_2^2\hat{\sigma}_{x_2}^2+2\hat{\beta}_1\hat{\beta}_2\hat{\sigma}_{x_1x_2}+\hat{\sigma}_\epsilon^2 \end{cases} \end{align*}\]
In comparison with conventional regression with fixed \(x\), when modeling \(x_1\), \(x_2\), and \(y\) with sample size \(n\), we are actually trying to fit a multiple regression with fixed \(x\)s that satisfies \(n\) unique equations simultaneously \[\begin{align*} \begin{cases} y_1 &= \hat{\beta}_0 + \hat{\beta_1}x_{11} + \hat{\beta_2}x_{12}\\ y_2 &= \hat{\beta}_0 + \hat{\beta_1}x_{21} + \hat{\beta_2}x_{22}\\ y_3 &= \hat{\beta}_0 + \hat{\beta_1}x_{31} + \hat{\beta_2}x_{32}\\ \vdots \\ y_n &= \hat{\beta}_0 + \hat{\beta_1}x_{n1} + \hat{\beta_2}x_{n2} \end{cases}. \end{align*}\] However, the equation system is unsolvable, so we solve the following equation instead, \[\begin{align*} \sum_{i=1}^{n}(y_i-\hat{\beta}_0 - \hat{\beta_1}x_{i1} - \hat{\beta_2}x_{i2})^2=0, \end{align*}\] this is the ordinary least square estimator for multiple linear regression with fixed \(x\)s.
2.3 Model all random variables jointly using multivariate normal distribution
In multiple regression with fixed \(x\), we only assume \(\epsilon\sim N(0,\sigma^2)\), indicating that we are using univariate normal distribution as the underlying distribution when modeling, that is \[\begin{align*} y_i - (\beta_0-\beta_1x_1-\cdots-\beta_px_p) = \epsilon_i \in N(0,1). \end{align*}\]
In SEM, when treating all variables (both IVs and DVs) as random variables, we can not use univariate normal distribution to model every random variable separately, because this is effectively treating them as independent to each other and against to the main goal of SEM. Instead, we use multivariate normal distribution to model all random variables jointly while taking their relationship into consideration.
Let’s denote all \(p\) independent variables as \(x_1\), \(\ldots\), \(x_p\), all \(m\) dependent variables as \(y_1\), \(\ldots\), \(y_m\), they jointly form a random vector that follows a multivariate normal distribution \[\begin{align*} \begin{pmatrix} x_1\\ \vdots\\ x_p\\ y_1\\ \vdots\\ y_m \end{pmatrix} \sim\quad MVN(\boldsymbol{0}, \boldsymbol{\Sigma}), \end{align*}\] where \[\begin{align*} \boldsymbol{\Sigma}=\begin{bmatrix} \sigma_{x_1}^2 & \cdots & \sigma_{x_1x_p} & \sigma_{x_1y_1} & \cdots & \sigma_{x_1y_m} \\ \vdots && \vdots&\vdots && \vdots \\ \sigma_{x_px_1} & \cdots & \sigma_{x_p}^2 & \sigma_{x_py_1} & \cdots & \sigma_{x_py_m}\\ \sigma_{y_1x_1} & \cdots & \sigma_{y_1x_p} & \sigma_{y_1}^2 & \cdots & \sigma_{y_1y_m}\\ \vdots && \vdots&\vdots && \vdots \\ \sigma_{y_mx_1} & \cdots & \sigma_{y_mx_p} & \sigma_{y_my_1} & \cdots & \sigma_{y_m}^2 \end{bmatrix}. \end{align*}\] If we imposed a structure, a statistical model with unknown parameters, upon all random variables to detail the relationship among them, we are effectively stating that we believe the relationship among the variables in interest can be explained by \(\boldsymbol{\Sigma}(\boldsymbol{\theta})\) on the population level, i.e. \(\boldsymbol{\Sigma}=\boldsymbol{\Sigma}(\boldsymbol{\theta}))\). Then we have, \[\begin{align*} \begin{pmatrix} x_1\\ \vdots\\ x_p\\ y_1\\ \vdots\\ y_m \end{pmatrix} \sim\quad MVN(\boldsymbol{0}, \boldsymbol{\Sigma}(\boldsymbol{\theta})). \end{align*}\]
2.4 Model identifiability
2.4.1 Number of information
For a univariate normal distribution, one only need two pieces of information to determine the distribution precisely, \(\mu\) and \(\sigma\). Because we are using no-mean-structure, we only need \(\sigma\) to pinpoint a normal distribution. Put another way, we only need one piece of information to depict one normally distributed random variable.
If we have two normally distributed random variables, they have their own variances, we now have two pieces of unique information. But these two variables can be correlated, quantifying by covariance or correlation, therefore we need one more piece of information to delineate the joint distribution.
In general, if we have \(p\) random variables, we have \(p(p+1)/2\) unique variances and covariances, that is, \(p(p+1)/2\) pieces of unique information.
2.4.2 Number of parameters
The number of parameters is the number of unknown quantities in the model, we need to estimate them from data. The number of parameters should not exceed the number of unique information, otherwise we will have an unsolvable model, see more detail in the following section.
2.4.3 Degree of freedom
- Just-identified model/unrestricted model/saturated model
The degree of freedom is the number of unique information left after estimating unknown parameters. In a multiple regression model \(y_i=\beta_1x_{1i}+\beta_2x_{2i}\), the number of unique information in the resulting \(\boldsymbol{\Sigma}(\boldsymbol{\theta})\) is 6 (all unrepeated elements in the lower triangle parts and the diagonal of \(\boldsymbol{\Sigma}(\boldsymbol{\theta})\)), the number of parameters is (\(\hat{\sigma}^2_{x_1}\), \(\hat{\sigma}^2_{x_2}\), \(\hat{\sigma}_{x_1x_2}\), \(\hat{\beta}_1\), \(\hat{\beta}_2\), and \(\hat{\sigma}^2_\epsilon\)). The degree of freedom is \(3(3+1)/2-6=0\). For models with \(df=0\), we call it just-identified model, or unrestricted model meaning no restriction is imposed on unknown parameter (see more details in the following text), or saturated model meaning it use all available information.
Note that the model-data fit of just-identified model can not be evaluated using likelihood ratio test (LRT) or any LRT-based method, because it is the full model, aka the best model we can fit to our data, and will always demonstrate perfect model-data fit (see more details in the likelihood ratio test chapter).
- Over-identified model/restricted model
If \(df>0\), the number of freely estimated parameters is less than the number of unique equations, this is the so-called over-identified model. For example, if we assumed \(x_2\) has not impact on \(y\) and fixed \(\hat{\beta}_{x_2y}=0\) (impose restriction on \(\hat{\beta}_{x_2y}\)), the number of parameters to be freely estimated decreases by 1, we end up with 1 more \(df\).
- Unidentifiable model
If \(df<0\), it’s called under-identified model and unsolvable.
Note that, although the reported \(df\) in Mplus is the same as in other software (i.e. lavaan), the way how Mplus calculates \(df\) is slightly different. In Mplus, the number of information is different for dependent and independent variables. Because the model does not impose restrictions on the parameters of the independent variables, their means, variances and covariances can be estimated separately as the sample values. Therefore the unique elements in the covariance matrix of independent variables are excluded when counting number of information.
For example, the number of information of ex3.11 (see the figure below) is \(3\times(3+1)/2+3\times3\), where \(6\) is the number of unique elements in the contrivance matrix of dependent variables \(y1\), \(y2\) and \(y3\), \(9\) is the number of covariances between \(x1\), \(x2\), \(x3\) and \(y1\), \(y2\), \(y3\).
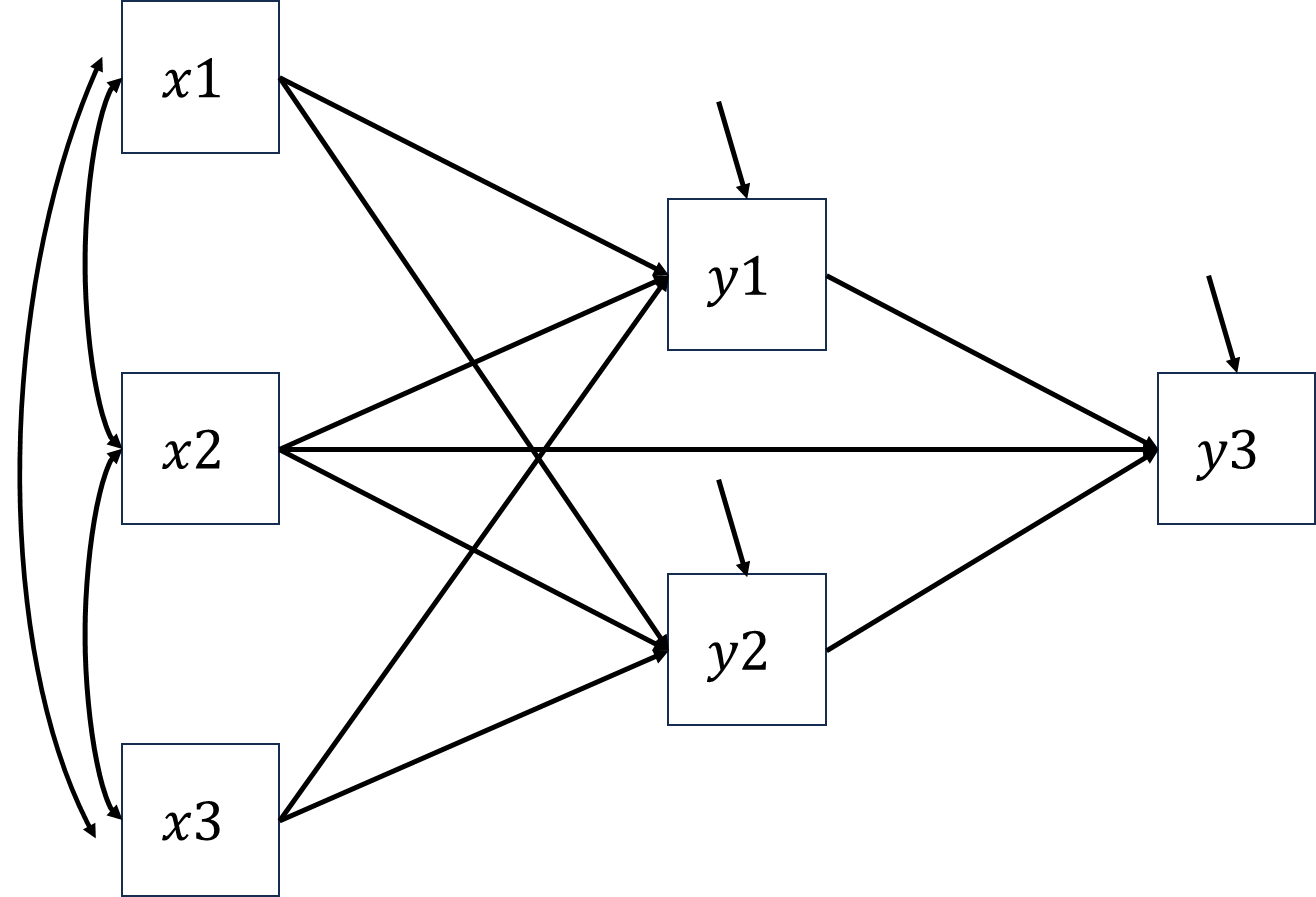
The corresponding element of \(\boldsymbol{\Sigma(\theta)}\) are marked in red, \[\begin{align*} \begin{bmatrix} \sigma_{x1}^2 & & & & & \\ \sigma_{x2x1} & \sigma_{x2}^2 & & & &\\ \sigma_{x3x1} & \sigma_{x3x1} & \sigma_{x3}^2 & & & \\ \color{red}\sigma_{y1x1} & \color{red}\sigma_{y1x2} & \color{red}\sigma_{y1x3} & \color{red}\sigma_{y1}^2 & & \\ \color{red}\sigma_{y2x1} & \color{red}\sigma_{y2x2} & \color{red}\sigma_{y2x3} & \color{red}\sigma_{y2y1} & \color{red}\sigma_{y2}^2 & \\ \color{red}\sigma_{y3x1} & \color{red}\sigma_{y3x2} & \color{red}\sigma_{y3x3} & \color{red}\sigma_{y3y1} & \color{red}\sigma_{y3y2} & \color{red}\sigma_{y3}^2 \end{bmatrix}. \end{align*}\]
Given the fact that there are \(9\) slopes and \(3\) residual variances to be estimated, \(df=15-12=3\).
2.5 Homework
Derive the covariance structure of following model, assume \(x\) is correlated with \(w\)
\[y=\beta_xx+\beta_ww+\beta_zz+e\]