7 Data Validation
Before analyzing survey data, it’s essential to validate that the data collected is accurate, complete, and follows the expected format. This step helps catch simple errors early, such as text in a numeric field, missing entries, or contradictory answers. For example, if someone types “twenty-five” instead of “25” in the “Age” field, the system should detect and correct it.
7.1 Importance of Data Quality
High-quality data forms the foundation of reliable analysis and sound decision-making. If the data contains errors, it can lead to incorrect insights and poor strategic choices. For instance, inaccurate customer satisfaction scores might suggest there’s a problem where none exists—or fail to reveal a real issue. Clean, accurate data improves credibility and saves time during analysis.
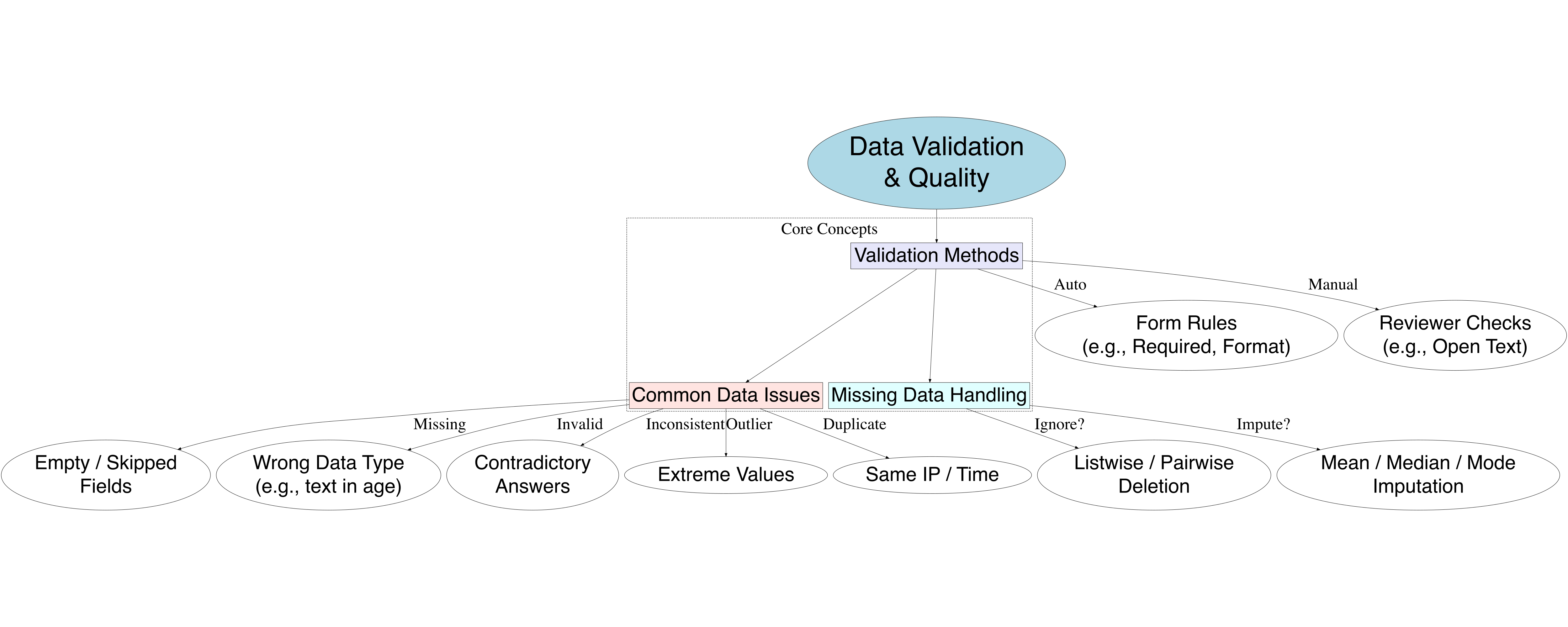
7.2 Common Survey Data Errors
Survey data is prone to several types of errors that can distort findings if not addressed. Identifying these issues early is critical for maintaining data integrity.
- Missing responses: Questions left blank by respondents.
- Invalid entries: Incorrect data types, such as entering “abc” for age.
- Inconsistent answers: Contradictions within a response, like stating “Not employed” but listing a workplace.
- Duplicate submissions: The same respondent completes the survey multiple times.
- Outliers: Unusual values that don’t align with the overall pattern, like a monthly income of “10,000,000” when most report between “10,000” and “100,000”.
7.3 Techniques for Data Cleaning
Cleaning data means correcting or removing errors so that the dataset is ready for analysis. This step is crucial to ensure consistency and reliability.
- Standardizing formats: For example, using the same date format such as “YYYY-MM-DD”.
- Fixing typos and inconsistencies: Like correcting misspellings or varying labels for missing values (“N/A”, “None”, “NA”).
- Using tools: Software like Excel, Google Sheets, or programming libraries (e.g., Python’s
pandas) help clean data efficiently.
7.4 Automated vs Manual Validation
Validation can be performed automatically or manually, depending on the type and complexity of data.
- Automated validation: Built-in rules or scripts to prevent invalid input, such as allowing only numbers in an age field.
- Manual validation: Human review is needed for open-ended or complex responses, such as interpreting the relevance of a text answer.
7.5 Handling Missing Data
Missing data is a common issue that must be handled thoughtfully to avoid biased results. The approach depends on the nature of the data and the research goals.
- Listwise deletion: Remove responses with missing data entirely.
- Imputation: Estimate the missing value, for example, by using the average value from similar respondents.
- Flagging: Mark missing values to exclude them from certain types of analysis.
7.6 Detecting Outliers & Inconsistencies
Outliers and logical inconsistencies can distort results and should be identified early.
- Outliers: Extremely high or low values, like someone reporting an age of 150.
- Inconsistencies: Conflicting answers, such as saying “No children” but listing “Childcare” as an expense.
These issues can be flagged for review or corrected if they appear to be errors.
7.7 Duplicate Response Detection
Duplicate responses can skew results and must be filtered out. This typically involves looking for patterns or clues that suggest repeated entries.
- Repeated IP addresses
- Identical answers across all questions
- Submissions within a short timeframe
For example, if two identical surveys come from the same IP address five minutes apart, one may be a duplicate and should be excluded.
7.8 Validation Features
Digital survey platforms come with built-in tools to help reduce data entry errors during the collection process. These tools are especially useful for real-time validation.
- Required fields: Prevent submission if a key question is skipped.
- Predefined answer formats: Like allowing only valid email addresses or numbers.
- Dropdown menus or multiple-choice fields: Limit the chance of invalid input.
- Skip logic: Hide or show questions based on previous responses to ensure relevance.
7.9 Ensuring Data Accuracy
Maintaining high data accuracy starts from the survey design phase and continues throughout data processing. Below are best practices that can help ensure reliable results:
- Design clear and simple questions to minimize misinterpretation.
- Pilot test the survey with a small group to identify confusing items.
- Train data collectors (if any) to avoid input errors.
- Use real-time validation tools such as mandatory fields or input restrictions.
- Document all validation and cleaning steps to support transparency and reproducibility.