$$\DeclareMathOperator{\Var}{Var}
\DeclareMathOperator{\Var}{Var} % DeclareMathOperator provide more space , see https://tex.stackexchange.com/questions/67506/newcommand-vs-declaremathoperator
\DeclareMathOperator{\var}{var}
\DeclareMathOperator{\Cov}{Cov}
\DeclareMathOperator{\cov}{cov}
\DeclareMathOperator{\E}{E}
\DeclareMathOperator{\bSigma}{\boldsymbol{\Sigma}}
\newcommand{\bs}{\boldsymbol}
\newcommand{\red}{\color{red}}
\newcommand{\green}{\color{green}}
\newcommand{\black}{\color{black}}
\newcommand{\grey}{\color{grey}}
\newcommand{\purple}{\color{purple}}
\newcommand{\blue}{\color{blue}}$$
1When \(y\) is continuous: general linear model
The term “general” linear model (GLM) usually refers to conventional linear regression models for a continuous response variable given continuous and/or categorical predictors. It includes multiple linear regression, as well as ANOVA and ANCOVA (with fixed effects only).
1.1 When \(x\) is continuous
For simplicity, multiple regression in this chapter is referring to multiple regression with fixed \(x\).
\[y_i=\beta_0+\beta_1x1_{i}+\cdots+\beta_px_{pi}+\epsilon_i,\] In the model above, we assume that \(\epsilon_i\) and \(y_i\) are random variables, \(x_i\)s are known constants. we have several assumptions:
\(E(\epsilon_i)=0\), or equivalently, \(E(y_i)=\beta_0+\beta_1x_i\);
\(\text{var}(\epsilon_i)=\sigma^2\), or equivalently, \(\text{var}(y_i)=\sigma^2\);
\(\text{cov}(\epsilon_i,\epsilon_j)=0\) for all \(i\neq j\), or, equivalently, \(\text{cov}(y_i, y_j)=0\).
Assumption 1 states that the value of \(y_i\) depends on all \(x_i\)s, all other variation in \(y_i\) is random error.
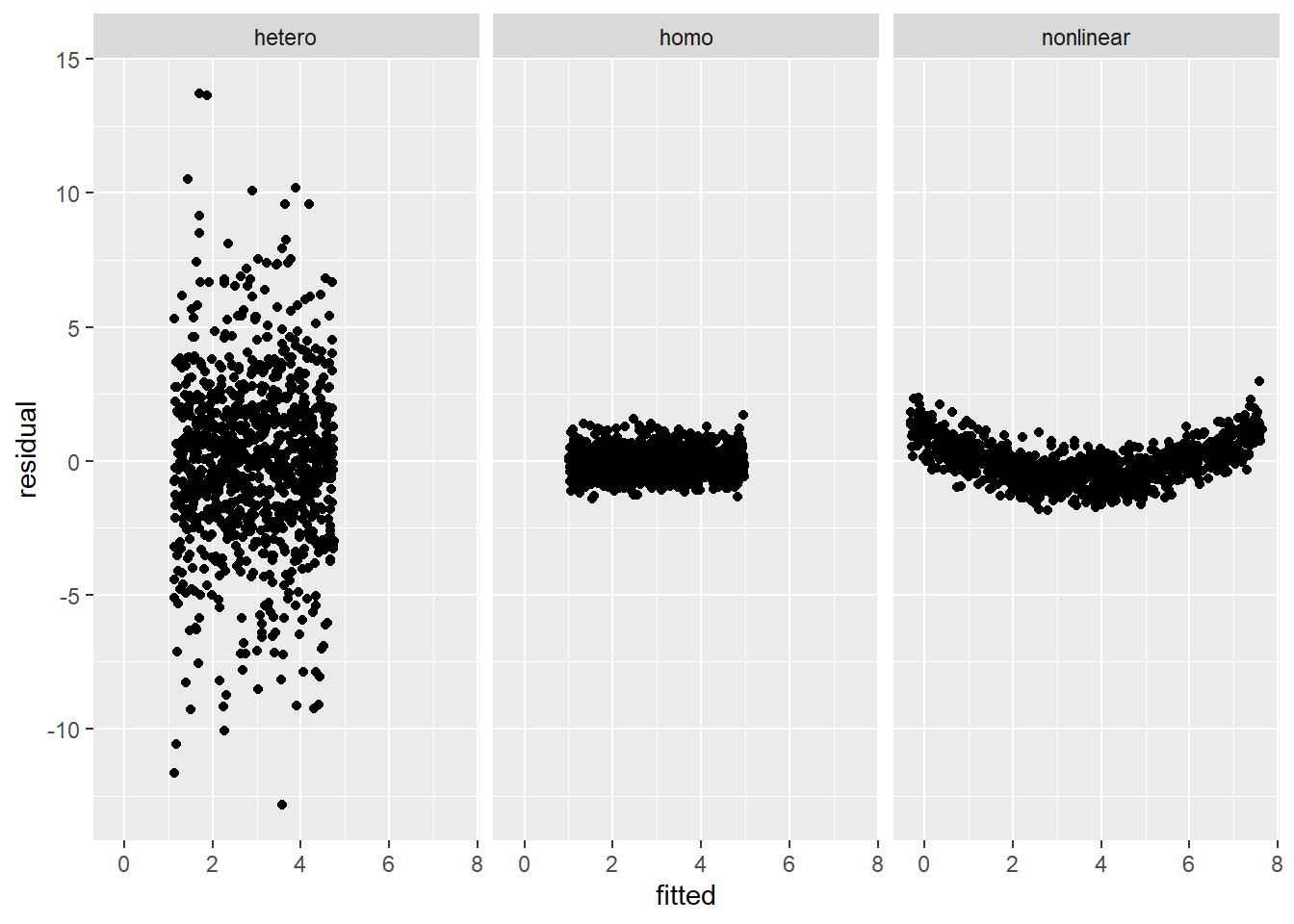
Assumption 2 states that \(\epsilon_i\)s have identical variance. This is also known as the assumption of homoscedasticity, homogeneous variance or constant variance.
After fitting a multiple regression model to a given data set we shall have \[\hat{y}_i=\hat{\beta}_0+\hat{\beta}_1x1_{i}+\cdots+\hat{\beta}_px_{pi}\] where \(\hat{\beta}_0\) and \(\hat{\beta}_j\) are the corresponding estimated intercept and slope, \(\hat{y}_i\) is the predicted \(y\) of \(x1_{i},\cdots,x_{pi}\) by the model above.
1.1.1 How to generate data using multiple regression
Simple regression
Generate a set of data that satisfy \(y = 1 + x1+\epsilon\).
set.seed(123)n <-300beta_0 <-1beta_1 <-1x1 <-1:nepsilon <-rnorm(n, mean =0, sd =1)y <- beta_0 + beta_1*x1 + epsilondf <-data.frame(x1 = x1, y = y)model_1 <-lm(y ~ x1, data = df)summary(model_1)
#>
#> Call:
#> lm(formula = y ~ x1, data = df)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -2.3053 -0.6368 -0.0705 0.5928 3.2000
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 0.9610022 0.1095565 8.772 <2e-16 ***
#> x1 1.0004880 0.0006309 1585.691 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Residual standard error: 0.9464 on 298 degrees of freedom
#> Multiple R-squared: 0.9999, Adjusted R-squared: 0.9999
#> F-statistic: 2.514e+06 on 1 and 298 DF, p-value: < 2.2e-16
coef(model_1)
#> (Intercept) x1
#> 0.9610022 1.0004880
Multiple regression
Generate a set of data that satisfy \(y = 1 + 2x1 + 3x2+\epsilon\)
#>
#> Call:
#> lm(formula = y ~ x1 + x2, data = df)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -2.64350 -0.62079 0.00596 0.68103 2.48339
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 1.1094805 0.1474924 7.522 6.44e-13 ***
#> x1 1.9999022 0.0006593 3033.340 < 2e-16 ***
#> x2 2.9996187 0.0006593 4549.654 < 2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Residual standard error: 0.9872 on 297 degrees of freedom
#> Multiple R-squared: 1, Adjusted R-squared: 1
#> F-statistic: 1.584e+07 on 2 and 297 DF, p-value: < 2.2e-16
1.1.2 Intuitive understanding of ordinary least square
Suppose we have \(y=\hat{a}x\), where \(a\) is parameter yet-to-estimate, \(x\) and \(y\) are observed variables. The straightforward estimator would be moving \(x\) to the left hand side by division \(\hat{a}=y/x\).
Similarly, given the matrix representation of multiple linear regression \(\boldsymbol{y}=\boldsymbol{X}\hat{\boldsymbol{\beta}}\), the simplest solution to derive the formula of \(\hat{\boldsymbol{\beta}}\) would be dividing \(\boldsymbol{y}\) by \(\boldsymbol{X}\), the operation corresponding to division in linear algebra is inversion. However, only square matrix with full rank is invertible. How to construct an invertible square matrix based on \(\boldsymbol{X}\)? \[\begin{align*}
\boldsymbol{X}'y&=\boldsymbol{X}'\boldsymbol{X}\hat{\boldsymbol{\beta}}\\
(\boldsymbol{X}'\boldsymbol{X})^{-1}\boldsymbol{X}'y&=\hat{\boldsymbol{\beta}}.
\end{align*}\]
we assume that \(y_i\) and \(\epsilon_i\) are random variables and that the values of \(x_i\) are known constants, which means that the same values of \(x1, x2, \ldots, x_n\) would be used in repeated sampling
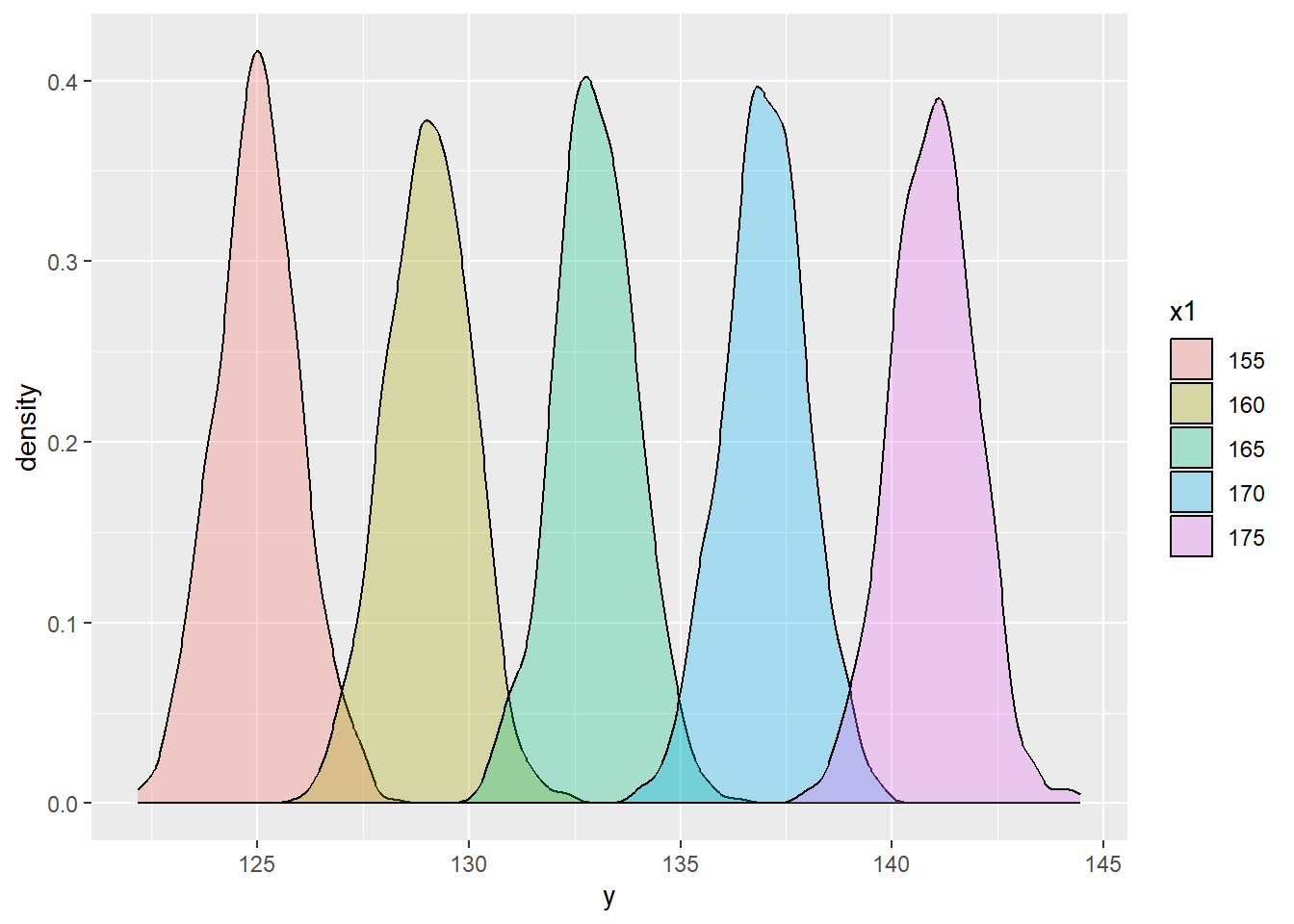
# predict the height of child by the average height of parentsset.seed(123)n_child_per_height <-1000beta_0 <-1beta_1 <-0.8height_ave_parents <-rep(seq(155, 175, by =5), each = n_child_per_height)epsilon <-rnorm(length(height_ave_parents), mean =0, sd =1)y <- beta_0 + beta_1*height_ave_parents + epsilondf <-data.frame(x1 = height_ave_parents, y = y)model_1 <-lm(y ~ x1, data = df)df$x1 <-factor(df$x1)ggplot(df, aes(x = y, fill = x1)) +geom_density(alpha =0.3)
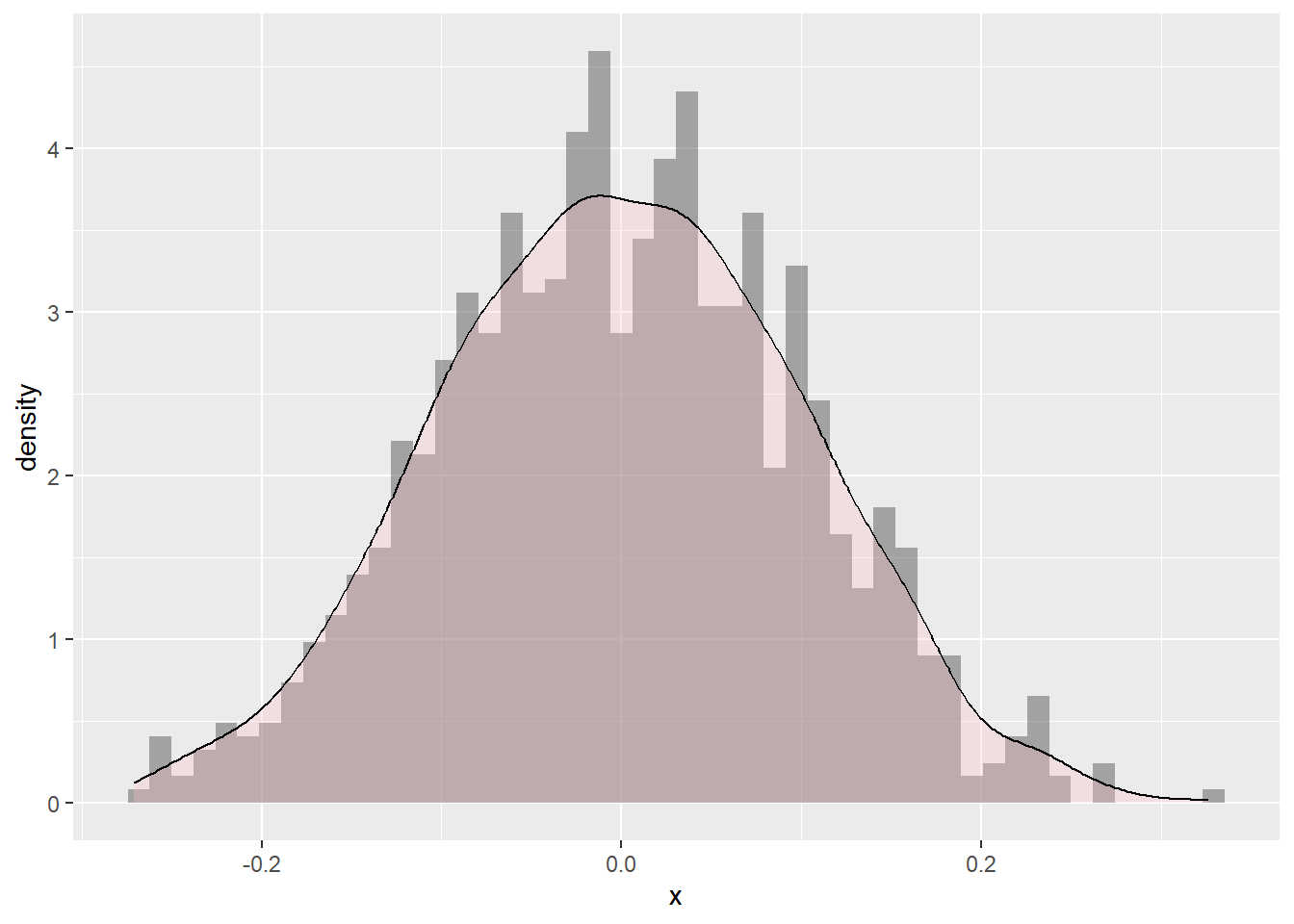
\(\hat{\epsilon}\)s are normally distributed but \(\boldsymbol{y}\) is not
The distribution of \(y\) is not necessarily normal, because
The interpretation of intercept \(\beta_0\) and slope \(\beta_j\)
Intercept
The intercept \(\beta_0\) could be viewed as the value of \(\hat{y}\) when all \(x\)s equal zero, it is only meaningful if it’s reasonable that all of the predictor variables in the data tested can actually be equal to zero. For example, if we fit a simple regression with height as \(x\) and weight as \(y\), certainly we can estimate a simple regression with intercept, but height equals 0 is make no sense at all. In this case, the intercept term simply anchors the regression line in the right place.
Slope
The slope \(\hat{\beta}_j\) signifies how much \(\hat{y}\) changes given a one-unit shift in \(x_j\) while holding other \(x\)s in the model constant. This property of holding the other independent variables constant is crucial because it allows you to assess the effect of each \(x\) on \(y\) in isolation from the others. If you are familiar with ANOVA, the interpretation of slope is similar to that of simple main effect.
In multiple regression, the relationship between \(x_j\) and \(y\) is linear, implying that the change of y in \(x_j\) is constant (\(\beta_j\) remains unchanged).
set.seed(123)n <-300beta_0 <-1beta_1 <-2beta_2 <-3x1 <-sample(n, n, replace =TRUE)x2 <-sample(n, n, replace =TRUE)y <- beta_0 + beta_1*x1 + beta_2*x2 +rnorm(n)df <-data.frame(x1 = x1, x2 = x2, y = y)fit <-lm(y ~ x1 + x2, data = df)coefs <-coef(fit)coefs
#>
#> Shapiro-Wilk normality test
#>
#> data: df_plot$x
#> W = 0.99807, p-value = 0.3153
ks.test(df_plot$x, y ="pnorm")
#>
#> Asymptotic one-sample Kolmogorov-Smirnov test
#>
#> data: df_plot$x
#> D = 0.021975, p-value = 0.7197
#> alternative hypothesis: two-sided
1.2 When \(x\) is categorical
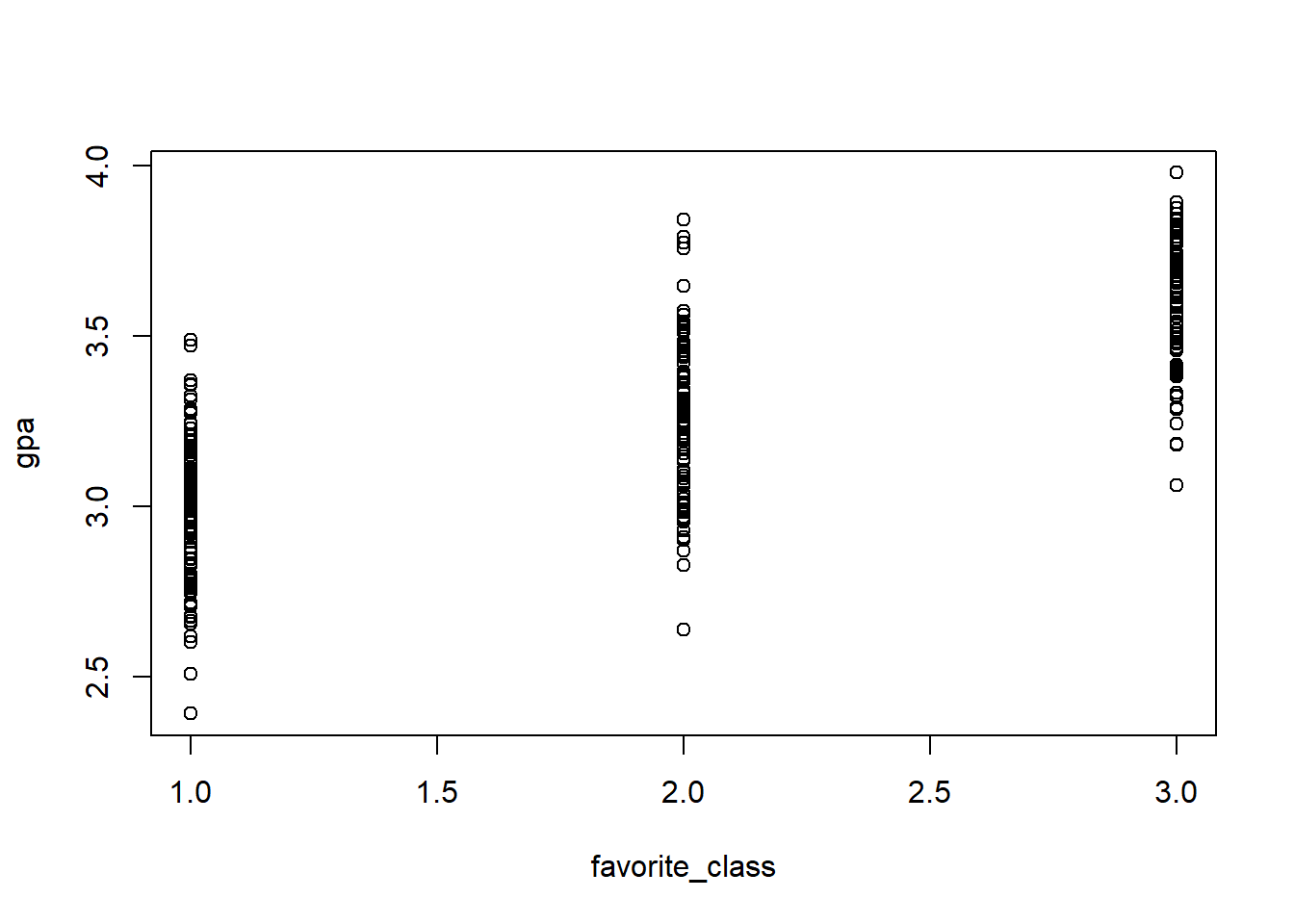
The validity of the interpretation of slope hinges on the interval nature of \(x\), since \(\hat{\beta}_j\) is interpreted as how \(\hat{y}\) would change in one-unit shift of \(x_j\) while holding other independent variables at constant. In other words, the high and low values of \(x\) are meaningful. However, when \(x\) is categorical (ordinal or nominal), the one-unit change of \(x\) becomes meaningless (ordinal variable has no equal intervals, nominal has neither euqal intervals and order), thus we need to use coding scheme to convert categorical variable into something interval. The the most widely used coding scheme is dummy coding.
The interpretation of regression coefficient with dummy variables
Before dummy coding, the regression model is \[\text{GPA}_i=\beta_0+\beta_1\text{FavoriteClass}_i+\epsilon_i.\] After dummy coding, assuming the science category (reference) is removed, the regression model becomes \[\text{GPA}_i=\beta_0+\beta_{d_{math}}d_{math}+\beta_{d_{language}}d_{language}+\epsilon_i.\]Coding session:
fit <-lm(gpa ~ dummy_math + dummy_language, data = df)cat("------------Fit multiple regression to dummy coded data------------\n")
#> ------------Fit multiple regression to dummy coded data------------
summary(fit)
#>
#> Call:
#> lm(formula = gpa ~ dummy_math + dummy_language, data = df)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -0.63165 -0.15259 0.00929 0.14700 0.57212
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 2.98646 0.01962 152.214 <2e-16 ***
#> dummy_math 0.28306 0.02872 9.855 <2e-16 ***
#> dummy_language 0.60238 0.02939 20.493 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Residual standard error: 0.2076 on 297 degrees of freedom
#> Multiple R-squared: 0.5859, Adjusted R-squared: 0.5832
#> F-statistic: 210.2 on 2 and 297 DF, p-value: < 2.2e-16
# recommended solutioncat("------------Recommended way of dummy coding in R------------\n")
#> ------------Recommended way of dummy coding in R------------
df$favorite_class <-factor(df$favorite_class)fit_factor <-lm(gpa ~ favorite_class, data = df)summary(fit_factor)
#>
#> Call:
#> lm(formula = gpa ~ favorite_class, data = df)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -0.63165 -0.15259 0.00929 0.14700 0.57212
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 2.98646 0.01962 152.214 <2e-16 ***
#> favorite_class2 0.28306 0.02872 9.855 <2e-16 ***
#> favorite_class3 0.60238 0.02939 20.493 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Residual standard error: 0.2076 on 297 degrees of freedom
#> Multiple R-squared: 0.5859, Adjusted R-squared: 0.5832
#> F-statistic: 210.2 on 2 and 297 DF, p-value: < 2.2e-16
For those whose favorite class is science, their \(\text{dmath}=0\) and \(\text{dlanguage}=0\), thus we have \[\begin{align*}
\hat{GPA}_{\text{Science}} &= \hat{\beta}_0+\hat{\beta}_{d_{math}}\times0+\hat{\beta}_{d_{language}}\times0 \\
&= \hat{\beta}_0,
\end{align*}\] that is, the group mean of students whose favorite class is science is \(\hat{\beta}_0\).
For those whose favorite class is math, their \(\text{dmath}=1\) and \(\text{dlanguage}=0\), thus we have \[\begin{align*}
\hat{GPA}_{d_{math}} &= \hat{\beta}_0+\hat{\beta}_{d_{math}}\times1+\hat{\beta}_{d_{language}}\times0 \\
&= \hat{\beta}_0 + \hat{\beta}_{d_{math}},
\end{align*}\] that is, the group mean of students whose favorite class is math is \(\hat{\beta}_0 + \hat{\beta}_{d_{math}}\).
For those whose favorite class is language, their \(\text{dmath}=0\) and \(\text{dlanguage}=1\), thus we have \[\begin{align*}
\hat{GPA}_{d_{language}} &= \hat{\beta}_0+\hat{\beta}_{d_{math}}\times0+\hat{\beta}_{d_{language}}\times1 \\
&= \hat{\beta}_0 + \hat{\beta}_{d_{language}},
\end{align*}\] that is, the group mean of students whose favorite class is math is \(\hat{\beta}_0 + \hat{\beta}_{d_{math}}\).
It is easy to see that the slope \(\hat{\beta}_{d_{math}}\) can be interpreted as the group mean difference between Math and Science (compare Math with Science); the slope \(\hat{\beta}_{d_{language}}\) can be interpreted as the group mean difference between Language and Science (compare Language with Science); that is why Science is called the reference group.
In summary, the model for the 3 groups directly provides 2 differences (reference category vs. each category), and indirectly provides another 1 differences (differences between non-reference groups).
All dummy variables (\(n_{\text{group}} - 1\)) representing the effect of group MUST be in the model at the same time for these specific interpretations to be correct!
Model parameters resulting from these dummy codes will not directly tell you about differences among non-reference groups.
Conceptual model VS Statistical model
Statistical models refer to those that correspond to the mathematical equations, while conceptual models represent the underlying theories or relationships that researchers are truly interested in.
Dummy coding alters only the statistical model because it increases the number of variables included in the regression analysis. The conceptual model, however, remains unchanged after coding. Researchers continue to investigate how a dependent variable (e.g., GPA) is influenced by background factors (e.g., favorite class).
1.3 Interaction effect
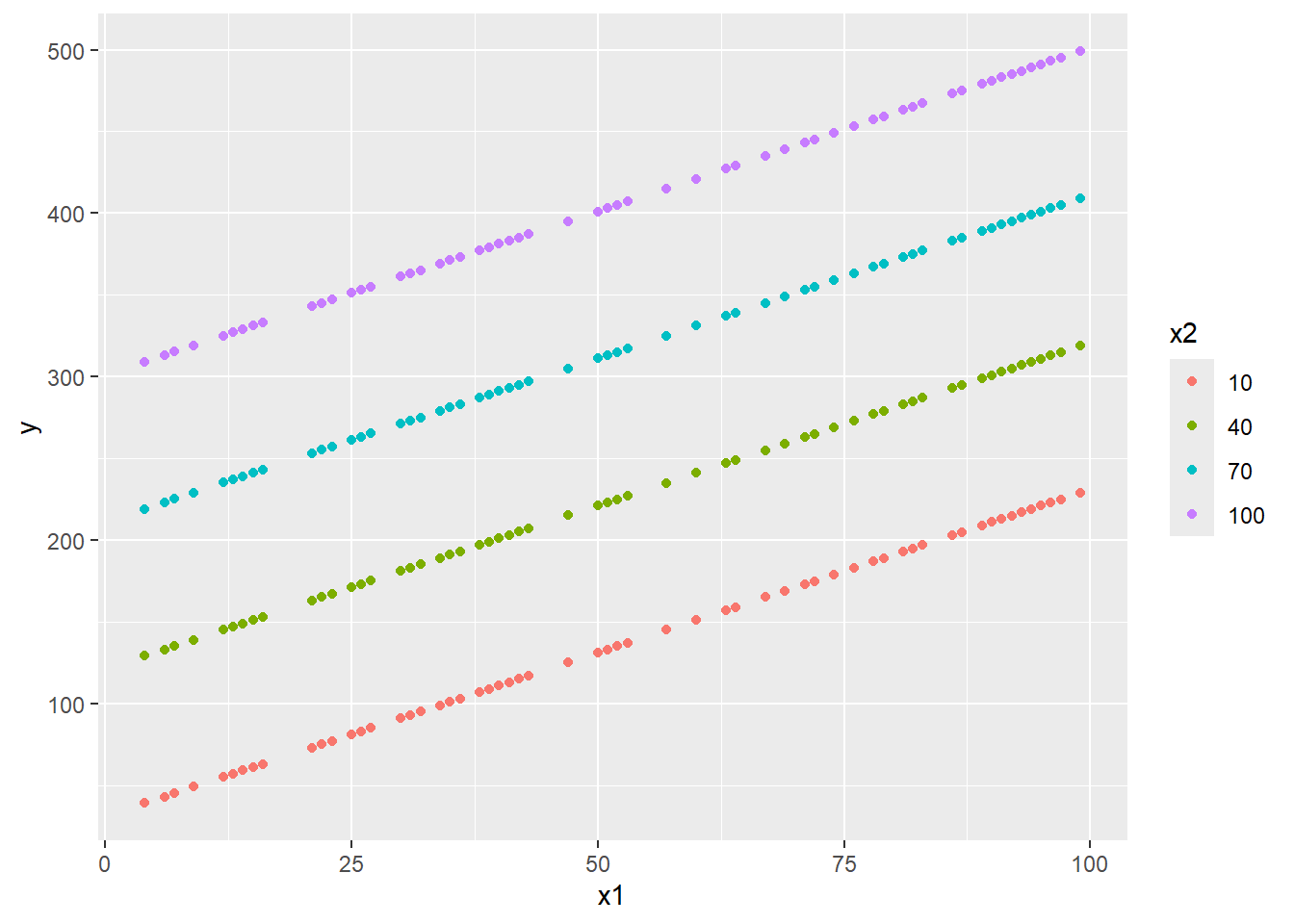
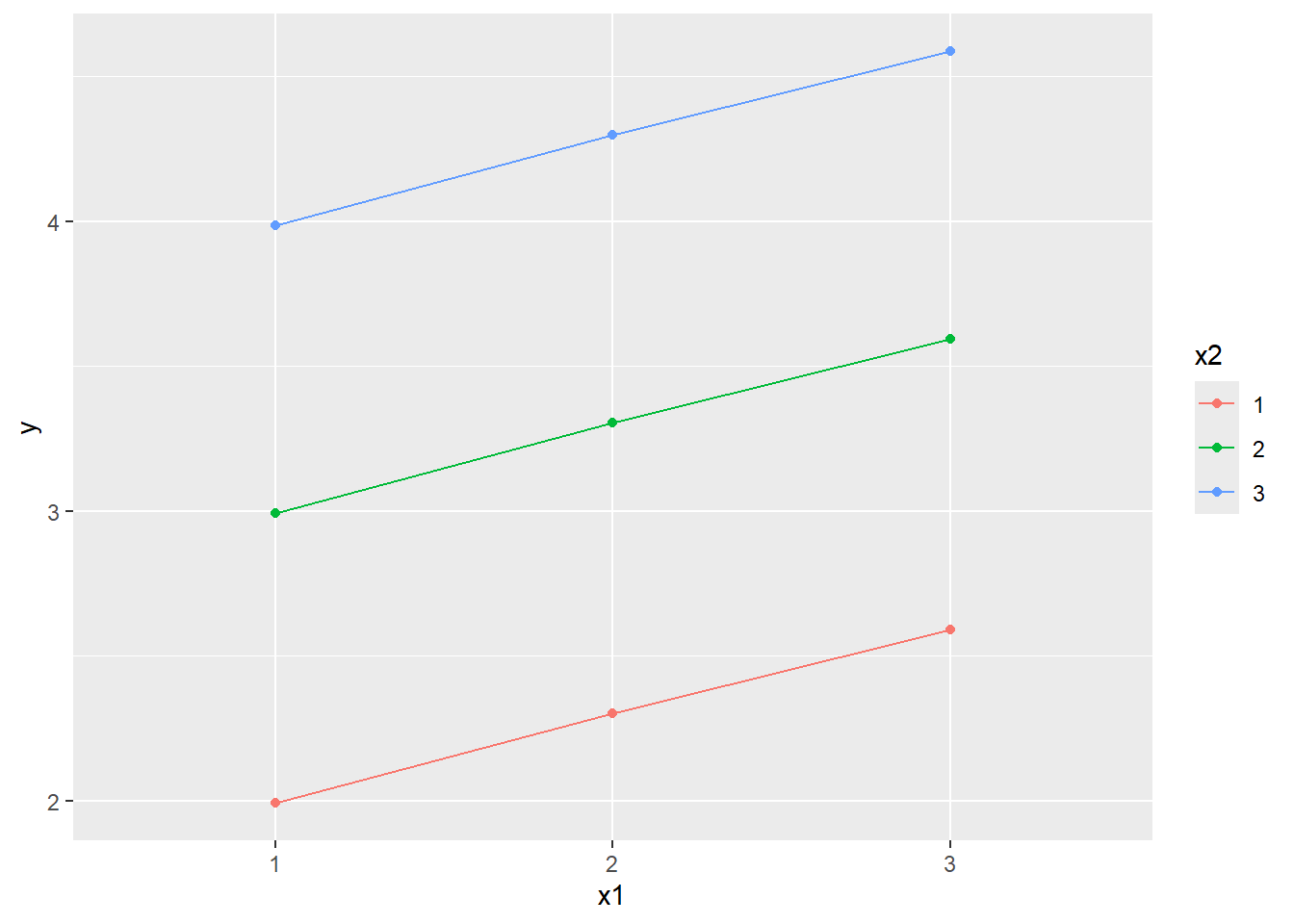
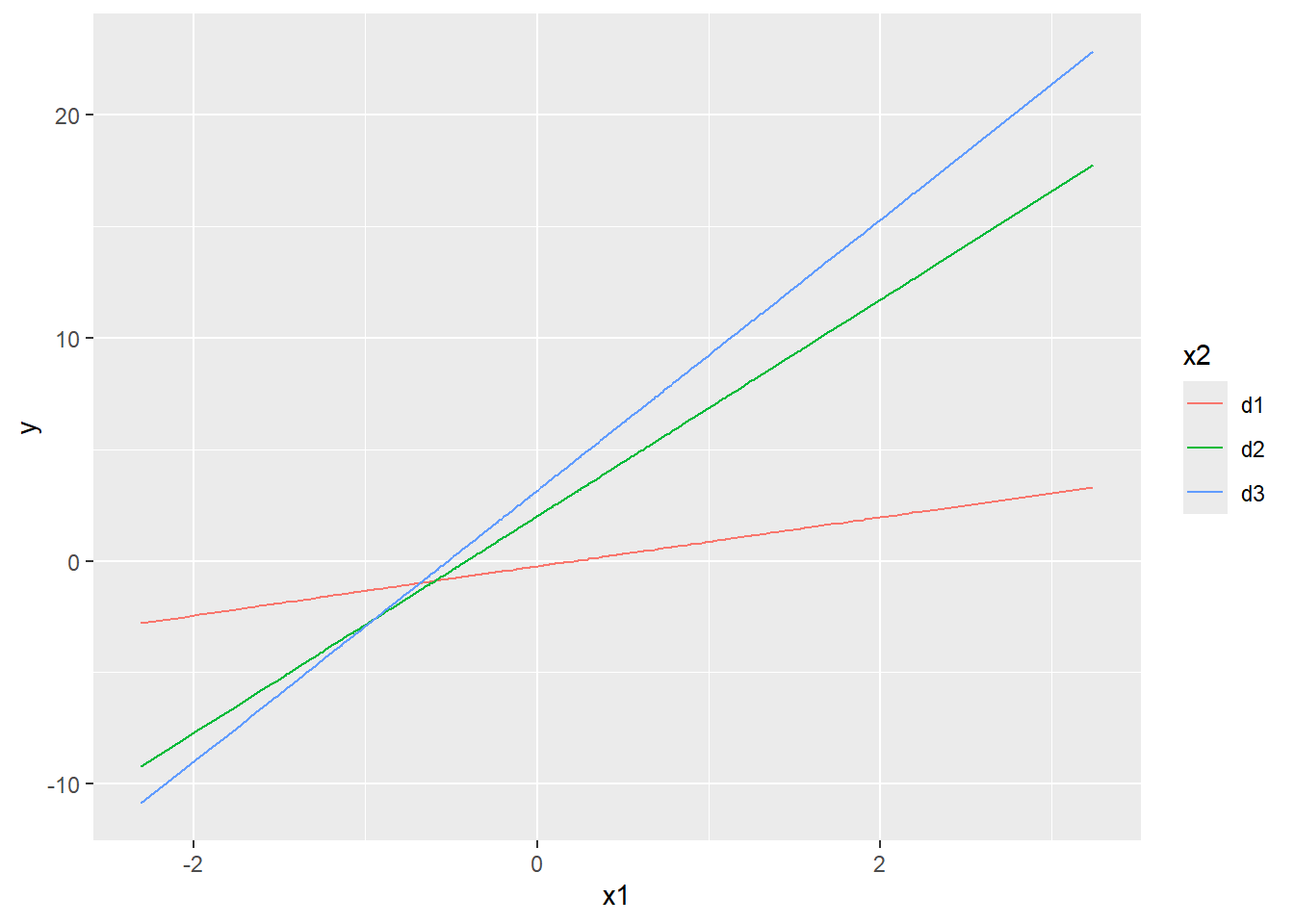
In multiple regression \[y_i=\beta_0+\beta_1x1_{i}+\cdots+\beta_px_{pi}+\epsilon_i,\]\(\beta_j\) is essentially the simple effect of \(x_j\). Multiple regression in this form is incapable of modeling interaction effect between any two independent variables. In the following visualization, it is easy to see that all lines are (destined to be) parallel to each other, implying that the model above is devoid of interaction effect.
To incorporate interaction effect into multiple regression, we need to manually construct product term to represent interaction effect. But why does product term represent interaction effect? Let’s take a multiple regression with two independent variables as an example.
1.3.1 When \(x\)s are all conitnuous
\[\begin{align*}
y_i&=\beta_0+\beta_1x1_{i}+\beta_2x2_{i}+\beta_3x1_{i}x2_{i}+\epsilon_i\\
y_i&=\beta_0+(\beta_1+\beta_3x2_{i})x1_{i}+\beta_2x2_{i}+\epsilon_i\\
y_i&=\beta_0+(\beta_2+\beta_3x1_{i})x2_{i}+\beta_1x1_{i}+\epsilon_i,
\end{align*}\] the effect of \(x1\) on \(y\) is now a function of \(x2\), and vice versa, implying that when modeling the relationship between \(x1\) and \(y\), we take the impact of \(x2\) into consideration by adding a product term.
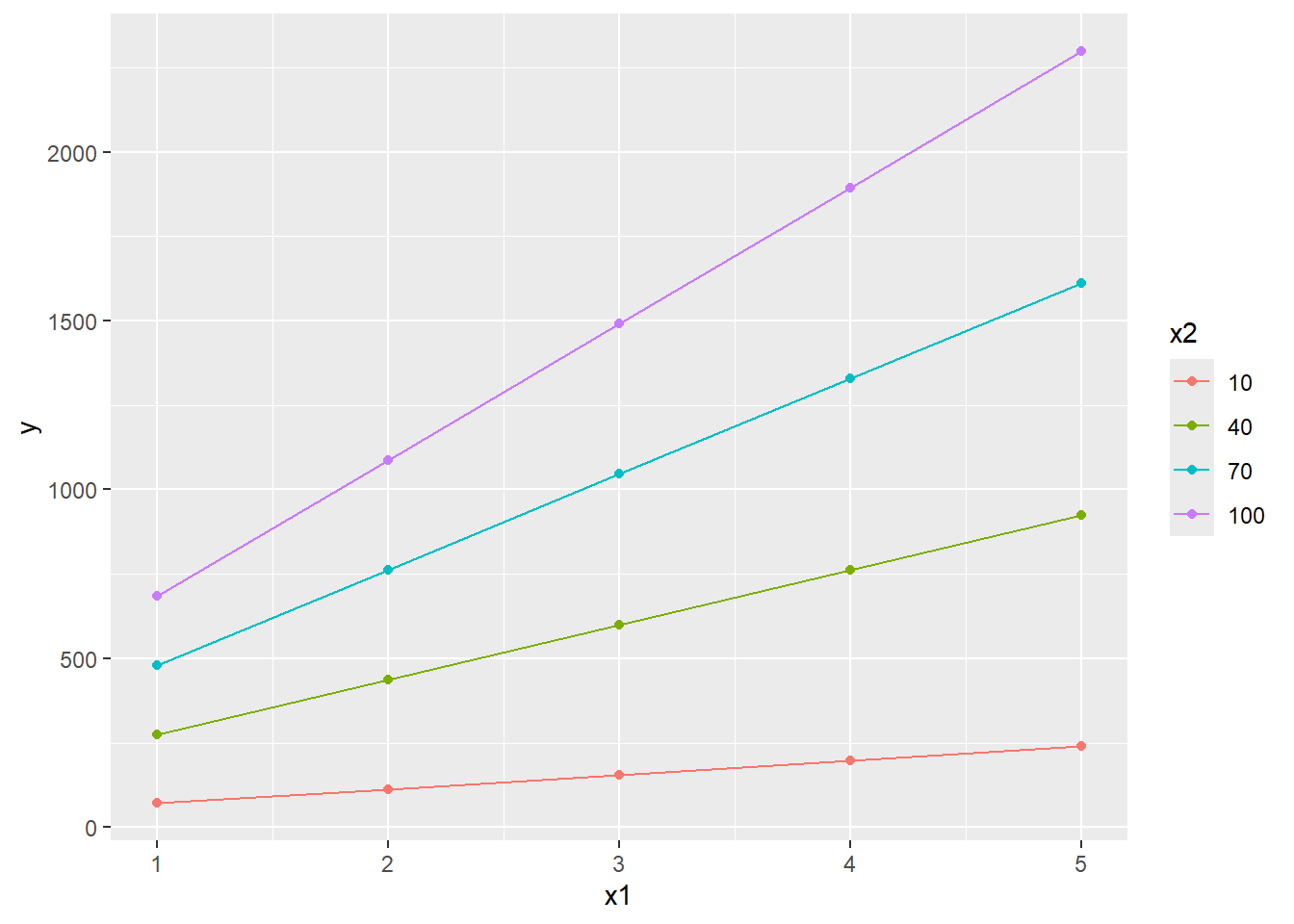
Simulate all \(y\)s given \(y_i=\beta_0+\beta_1x1_{i}+\beta_2x2_{i}+\beta_3x1_{i}x2_{i}+\epsilon_{i}\).
Conduct multiple regression with and without interaction effect using Mplus.
For non-quant students, do step 4 only.
Simulation: fit multiple regression with and without product term to data that contains interaction effects
#> ------------With product term------------
#>
#> Call:
#> lm(formula = y ~ x1 + x2 + x1x2, data = df)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -3.2212 -0.6448 0.0057 0.6542 2.7976
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 1.46987 0.55070 2.669 0.00893 **
#> x1 1.99392 0.17299 11.526 < 2e-16 ***
#> x2 2.79005 0.17030 16.383 < 2e-16 ***
#> x1x2 4.01378 0.05182 77.459 < 2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Residual standard error: 1.071 on 96 degrees of freedom
#> Multiple R-squared: 0.9989, Adjusted R-squared: 0.9989
#> F-statistic: 3.025e+04 on 3 and 96 DF, p-value: < 2.2e-16
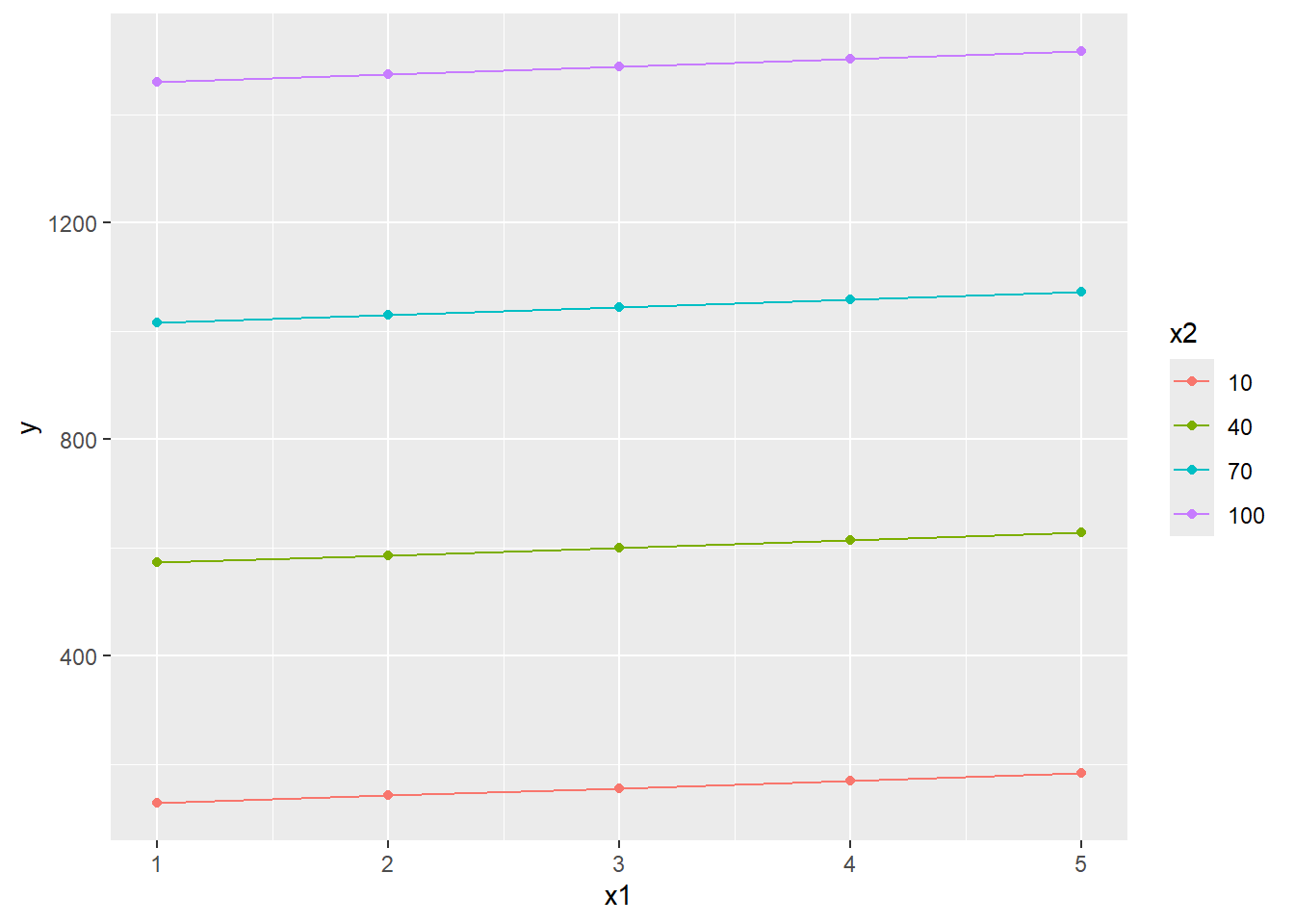
#> ------------Same data, without product term------------
#>
#> Call:
#> lm(formula = y ~ x1 + x2, data = df)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -17.6816 -4.8886 -0.4076 6.2894 16.4259
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) -33.7038 2.4699 -13.65 <2e-16 ***
#> x1 14.0043 0.6081 23.03 <2e-16 ***
#> x2 14.7985 0.5588 26.48 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Residual standard error: 8.492 on 97 degrees of freedom
#> Multiple R-squared: 0.9329, Adjusted R-squared: 0.9315
#> F-statistic: 674.2 on 2 and 97 DF, p-value: < 2.2e-16
1.3.2 When \(x\)s are all categrocial
1.3.2.1 No product term
Suppose we have two categorical independent variables \(x1\) and \(x2\), both of which have 3 levels (1, 2, 3). To model \(x1\) and \(x2\) using a linear regression, we shall use two out of three dummy variables for each \(x\) (reference categories all = 1). Thus we have \[y_i=\beta_0+\beta_1d2x1_{i}+\beta_2d3x1_{i}+\beta_3d2x2_{i}+\beta_4d3x2_{i}+\epsilon_i.\]
When \(x1=1\) and \(x2=1\), \(d2x1_{i}=d3x1_{i}=d2x2_{i}=d3x2_{i}=0\), thus the predicted mean of this group is \[\hat{y}_{x1=1,x2 =1}=\hat{\beta}_0.\]
When \(x1=2\) and \(x2=1\), \(d2x1_{i}=1\), \(d3x1_{i}=d2x2_{i}=d3x2_{i}=0\), thus the mean of this group is \[\hat{y}_{x1=2,x2 =1}=\hat{\beta}_0+\hat{\beta}_1.\]
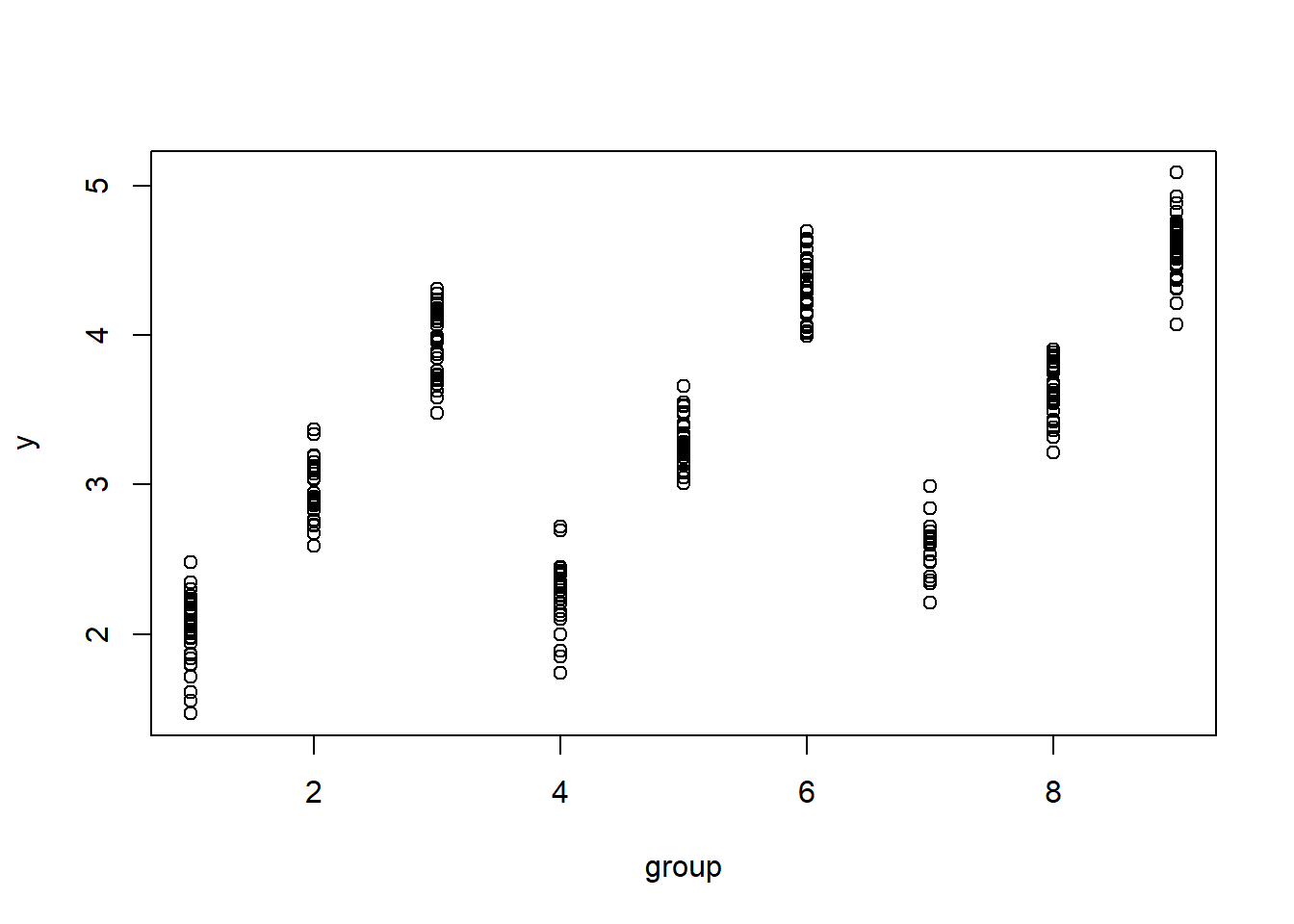
Likewise, we have the predicted mean of 9 groups as follow:
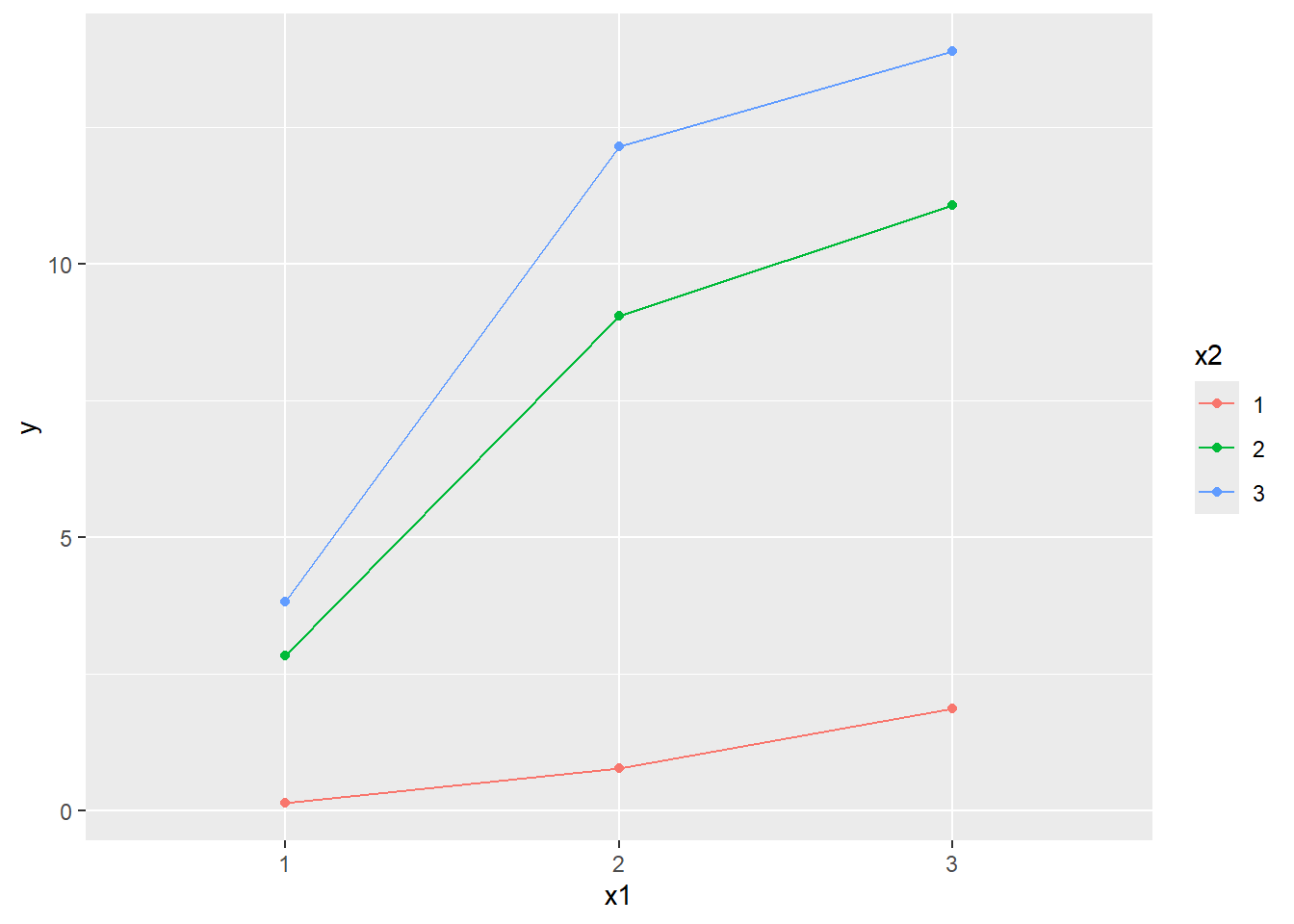
Randomly assign 300 simulated students to these 9 groups and generate their \(y\) accordingly,
Dummy code group \(x1\) and \(x2\), reference category = 1.
Perform multiple regression without interaction effect using Mplus.
For non-quant students, do steps 3-4.
#>
#> Call:
#> lm(formula = y ~ x1 + x2, data = df)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -0.56562 -0.12551 0.00952 0.13753 0.49988
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 1.99205 0.02418 82.38 <2e-16 ***
#> x12 0.31162 0.02741 11.37 <2e-16 ***
#> x13 0.60050 0.02837 21.17 <2e-16 ***
#> x22 1.00135 0.02885 34.71 <2e-16 ***
#> x23 1.99361 0.02875 69.35 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Residual standard error: 0.197 on 295 degrees of freedom
#> Multiple R-squared: 0.9525, Adjusted R-squared: 0.9518
#> F-statistic: 1478 on 4 and 295 DF, p-value: < 2.2e-16
Again, interaction effect is beyond the reach of a multiple regression without product term.
1.3.2.2 Product terms added
Now, we manually create the product terms \[\begin{align*}
y_i&=\beta_0+\beta_1d2x1_{i}+\beta_2d3x1_{i}+\beta_3d2x2_{i}+\beta_4d3x2_{i}+\\
&\quad \enspace \beta_5d2x1_{i}d2x2_{i}+\beta_6d2x1_{i}d3x2_{i}+\beta_7d3x1_{i}d2x2_{i}+\beta_8d3x1_{i}d3x2_{i}+\\
&\quad \enspace \epsilon_i.\\
\end{align*}\]
Note
Note that, we need all four product terms to model the interaction effect of \(x1\) and \(x2\).
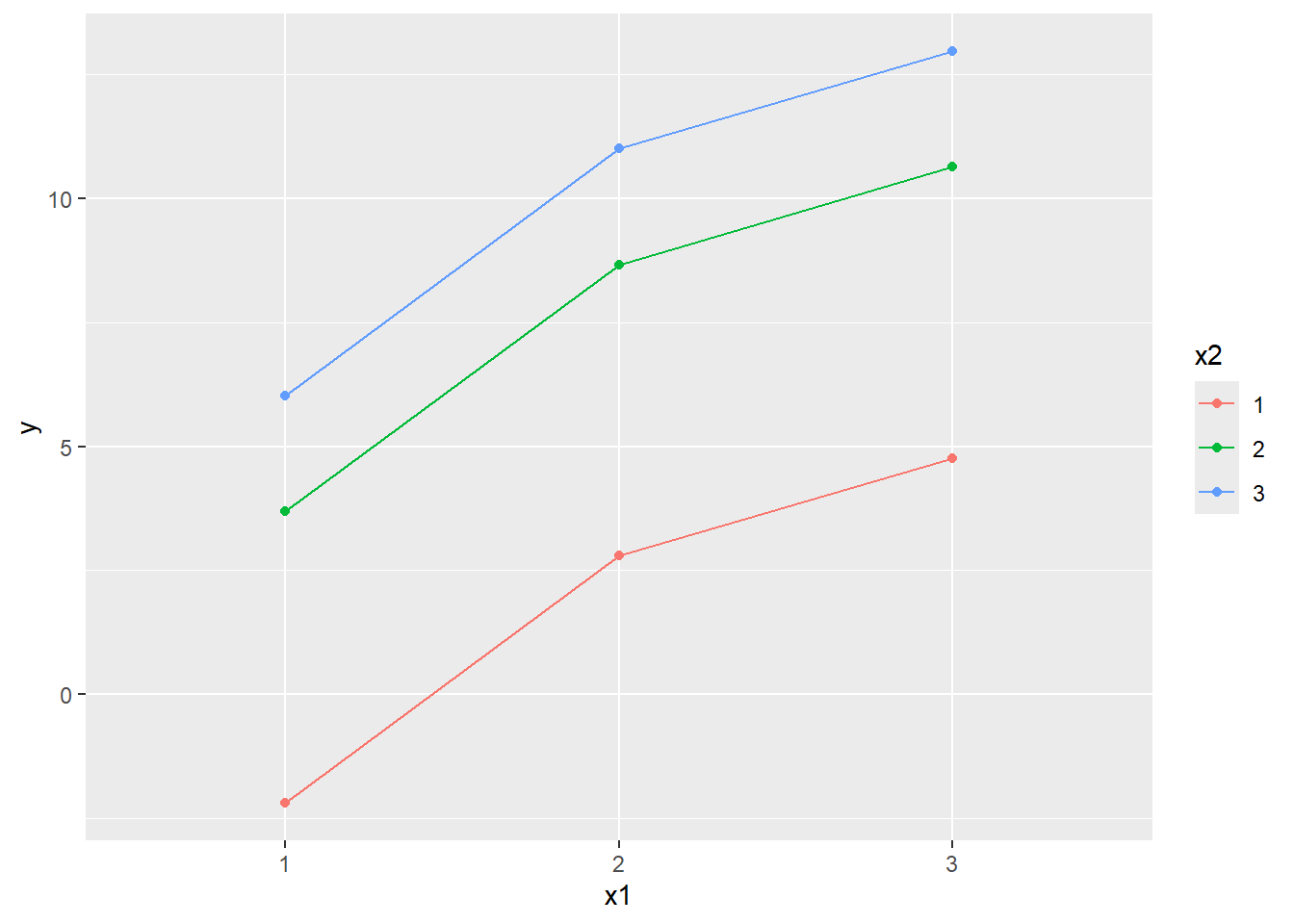
No surprise, when \(x1=1\) and \(x2=1\), \(d2x1_{i}=d3x1_{i}=d2x2_{i}=d3x2_{i}=0\), thus the predicted mean of this group is still the intercept \[\hat{y}_{x1=1,x2 =1}=\hat{\beta}_0.\]
When \(x1=2\) and \(x2=1\), \(d2x1_{i}=1\), \(d3x1_{i}=d2x2_{i}=d3x2_{i}=0\), thus the mean of this group is \[\hat{y}_{x1=2,x2 =1}=\hat{\beta}_0+\hat{\beta}_1.\]
When \(x1=2\) and \(x2=2\), \(d2x1_{i}=d2x2_{i}=1\), \(d3x1_{i}=d3x2_{i}=0\), thus the mean of this group is \[\hat{y}_{x1=2,x2=2}=\hat{\beta}_0+\hat{\beta}_1+\hat{\beta}_3+\color{red}\hat{\beta}_5,\] where the red part represent the interaction effect between \(x1\) and \(x2\) when \(x1=2\) and \(x2=2\).
After including product terms, the predicted mean of 9 groups now become
#> ------------Multiple regressio without product terms------------
#>
#> Call:
#> lm(formula = y ~ x1 + x2, data = df)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -4.7154 -1.2654 0.1351 1.3760 4.6007
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) -2.2033 0.2314 -9.523 <2e-16 ***
#> x12 4.9901 0.2623 19.026 <2e-16 ***
#> x13 6.9570 0.2714 25.633 <2e-16 ***
#> x22 5.8847 0.2760 21.322 <2e-16 ***
#> x23 8.2169 0.2751 29.874 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Residual standard error: 1.885 on 295 degrees of freedom
#> Multiple R-squared: 0.8713, Adjusted R-squared: 0.8696
#> F-statistic: 499.3 on 4 and 295 DF, p-value: < 2.2e-16
1.3.3 When having continuous \(x\) and categorical \(x\) at the same time
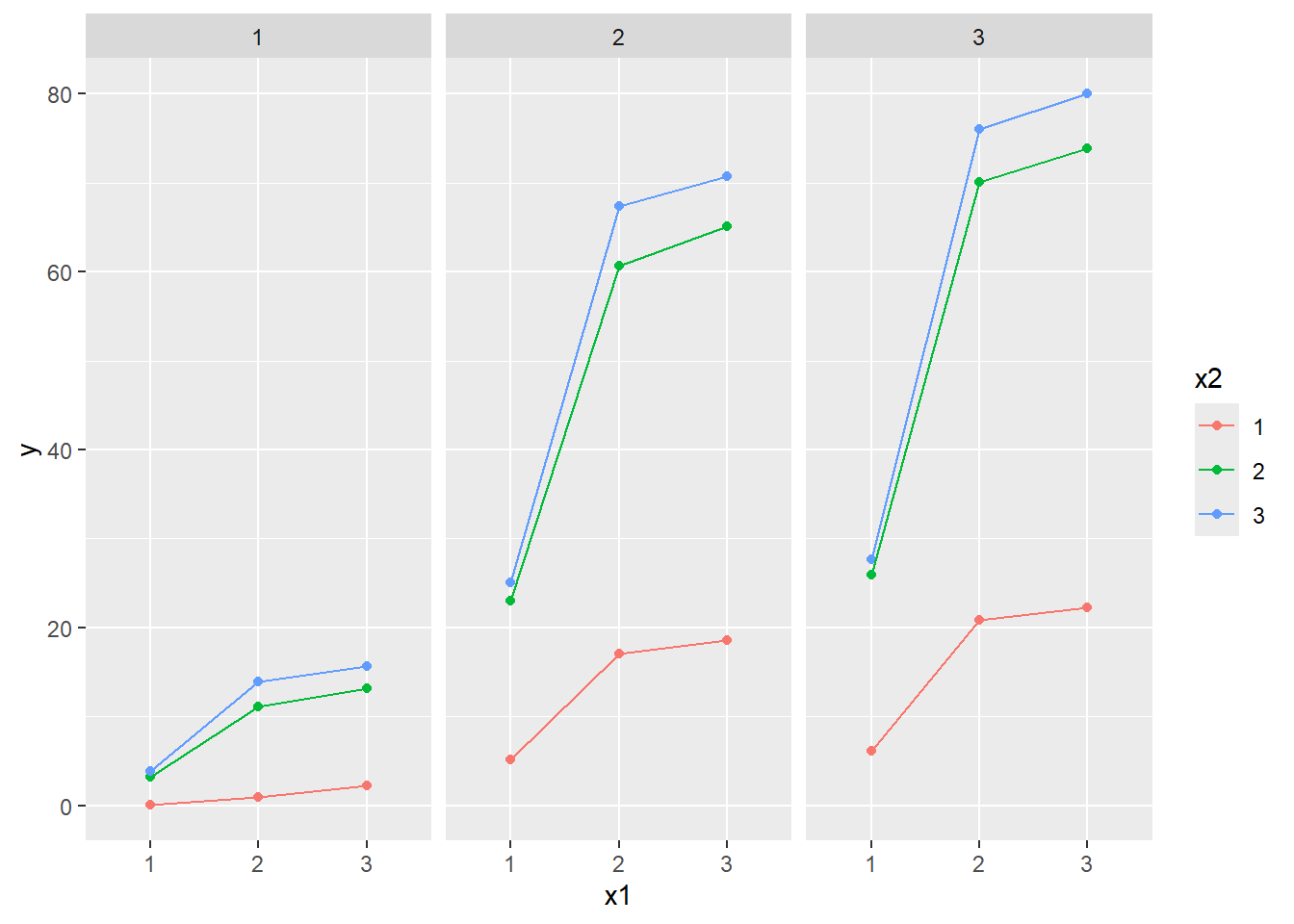
Assume we have one dependent variable \(y\) and two independent variables, \(x1\) and \(x2\), where \(x1\) is continuous, \(x2\) is a 3-level categorical variable. Let’s model these 3 variables with a multiple linear regression with interaction effect. First, we should dummy code \(x2\) as \(d2x2\) and \(d3x2\) while keeping the 1st category as reference. Then we have \[\begin{align*}
y_i&=\beta_0+\beta_1x1+\beta_2d2x2+\beta_3d3x2+\beta_4x1d2x2+\beta_5x1d3x2+\epsilon_i.\\
\end{align*}\] When \(x2=1\), \(d2x2=d3x2=0\), \[\begin{align*}
y_i&=\beta_0+\beta_1x1+\epsilon_i.\\
\end{align*}\] When \(x2=2\), \(d2x2=1\) and \(d3x2=0\), \[\begin{align*}
y_i&=\beta_0+\beta_1x1+\beta_2+\beta_4x1+\epsilon_i\\
&=(\beta_0+\beta_2)+(\beta_1+\beta_4)x1+\epsilon_i.
\end{align*}\] When \(x2=3\), \(d2x2=0\) and \(d3x2=1\), \[\begin{align*}
y_i&=\beta_0+\beta_1x1+\beta_3+\beta_5x1+\epsilon_i\\
&=(\beta_0+\beta_3)+(\beta_1+\beta_5)x1+\epsilon_i,
\end{align*}\] Therefore, if interaction effect between \(x1\) and \(x2\) was significant, we shall observe different regression relationships between \(x1\) and \(y\) at different categories of \(x2\).
Suppose we have three categorical independent variables \(x1\), \(x2\) and \(x_3\), all of which have 3 levels (1, 2, 3). To fit an linear regression, we shall use two out of three dummy variables for each \(x\) (reference categories all = 1). Thus \[\begin{align*}
y_i&=\beta_0+\beta_1d2x1_{i}+\beta_2d3x1_{i}+\beta_3d2x2_{i}+\beta_4d3x2_{i}+\beta_5d2x3_{i}+\beta_6d3x3_{i}+\\
&\text{x1x2}\\
&\quad \enspace \beta_7d2x1_{i}d2x2_{i}+\beta_8d2x1_{i}d3x2_{i}+\beta_9d3x1_{i}d2x2_{i}+\beta_{10}d3x1_{i}d3x2_{i}+\\
&\text{x1x3}\\
&\quad \enspace \beta_{11}d2x1_{i}d2x3_{i}+\beta_{12}d2x1_{i}d3x3_{i}+\beta_{13}d3x1_{i}d2x3_{i}+\beta_{14}d3x1_{i}d3x3_{i}+\\
&\text{x2x3}\\
&\quad \enspace \beta_{15}d2x2_{i}d2x3_{i}+\beta_{16}d2x2_{i}d3x3_{i}+\beta_{17}d3x2_{i}d2x3_{i}+\beta_{18}d3x2_{i}d3x3_{i}+\\
&\text{x1x2x3}\\
&\quad \enspace+\beta_{19}d2x1_{i}d2x2_{i}d2x3_{i}+\beta_{20}d3x1_{i}d2x2_{i}d2x3_{i}+\\
&\quad \enspace \beta_{21}d2x1_{i}d3x2_{i}d2x3_{i}+\beta_{22}d3x1_{i}d3x2_{i}d2x3_{i}+\\
&\quad \enspace \beta_{23}d2x1_{i}d2x2_{i}d3x3_{i}+\beta_{24}d3x1_{i}d2x2_{i}d3x3_{i}+\\
&\quad \enspace \beta_{25}d2x1_{i}d3x2_{i}d3x3_{i}+\beta_{26{}}d3x1_{i}d3x2_{i}d3x3_{i}+\\
&\quad \enspace \epsilon_i.\\
\end{align*}\]
#> ------------Multiple regressio with product terms------------
#> ------------Dummy coding using factor------------
When doing empirical research, it is not unusual to have more than 3 categorical \(x\)s. The resulting regression model quickly becomes cumbersome to deal with because of many interaction effects involved. In SPSS, the default of ANOVA is including all possible interaction effects. In ANOVA, each hypothesis corresponds to an effect (main, interaction, simple), the default setting of SPSS easily leads to redundant hypotheses when having multiple categorical \(x\)s. However, given the confirmatory nature (testing hypothesis) of empirical research in psychology, the number of focal hypotheses is usually limited in a single study. To reduce the number of hypotheses, a common practice is removing all interaction effects that are not of interest. Following is an example of a 3-way design with a specific second order interaction effect removed.
# Straight forward solution in Rset.seed(123)n <-900df <-data.frame(program =sample(1:3, size = n, replace =TRUE),school =sample(1:3, size = n, replace =TRUE),division =sample(1:3, size = n, replace =TRUE),height =sample(3:7, size = n, replace =TRUE))df$program <-factor(df$program)df$school <-factor(df$school)df$division <-factor(df$division)# Default: model all interaction effects at oncefit_all <-lm( height ~ program + school + division + program*school*division, data = df)summary(fit_all)
# remove unwanted interaction effect by using the update() function# e.g. remove the interaction effect of program and divisionfit_part <-update(fit_all, ~.-program:division)summary(fit_part)
# Workaround solution for Mplus user# Step 1: create the design matrix with all terms includedterm_all <-model.matrix( height ~ program + school + division + program*school*division, data = df)head(term_all)# Step 2: remove all terms associated with unwanted interaction effectsid_column_omit <-grep("program[2-3][:]division[2-3]", colnames(term_all))xs <- term_all[, -id_column_omit]# Mplus model intercept in default, we need to remove the intercept # column from design matrix to avoid having redundant intercept# Step 3: combine the model matrix with dependent variabledf_part <-cbind(xs[, -1], df$height)head(df_part)# Step 4: save the data as local filewrite.table( df_part,file =paste(getwd(),"/data/1y 3xs_categorical_interaction_remove_unwanted_interaction.txt",sep ="" ),col.names =FALSE,row.names =FALSE)