Rozdział 4 Zmienna celu w modelach scoringowych
4.1 Dobry i zły klient, zaniechanie spłaty (default)
W przypadku scoringu kredytowego tradycyjnie mówi się o klientach lub obserwacjach złych (bad) i dobrych (good). Jako złego klienta można traktować takiego, który zaniechał spłaty (ang. default — zaniechanie). W praktyce default może oznaczać, przykładowo, opóźnienie w spłacie większe niż 90 dni w ciągu pierwszych dwunastu miesięcy po uruchomieniu kredytu.
Zaniechanie realizacji zobowiązań kredytowych (default) rozpoznajemy najczęściej po opóźnieniu w spłacie. Typowy sposób liczenia opóźnienia to opóźnienie w dniach (skrót DPD, days past due oznacza dni opóźnienia). Opóźnianie się w spłacie nazywane jest czasem szkodowością (ang. delinquency). Typowe poziomy opóźnienia to 30, 60, 90, 120 dni (wielokrotności trzydziestki, czyli w przybliżeniu pełne miesiące). O ile określenia default używa się w przypadku dużych opóźnień (90 dni), o tyle scoring kredytowy może być budowany na podstawie niższych poziomów szkodowości, np. opóźnień 30-dniowych.
Zadaniem w modelowaniu scoringowym jest więc utworzenie rankingu klientów, kredytów, wniosków kredytowych według prawdopodobieństwa złego lub dobrego. Zgodnie z przyjętą konwencją, scoring kredytowy będzie działał poprawnie, jeżeli częstość złych (ang. bad rate) będzie wyższa dla obserwacji z niższą oceną punktową, a niższa dla obserwacji o wysokiej ocenie.
4.2 Szansa, log-odds
Zamiast częstości (prawdopodobieństwa) złego stosuje się czasem szansę (ang. odds) lub logarytm naturalny szansy (ang. log-odds).
Jeżeli prawdopodobieństwo (lub częstość) złego dla danej obserwacji lub grupy obserwacji oznaczymy symbolem \(p_B\), a prawdopodobieństwo dobrego symbolem \(p_G\), gdzie \(p_G = 1 - p_B\), to szanse złego i dobrego dla tej samej obserwacji/grupy (\(o_B\) i \(o_G\)) możemy zdefiniować następująco:
\[o_B = \frac{p_B}{1-p_B}=\frac{p_B}{p_G}; \qquad o_G = \frac{p_G}{1-p_G}=\frac{p_G}{p_B}\]
Warto zauważyć, że szansa złego do odwrotność szansy dobrego:
\[o_B = \frac{1}{o_G}\] Przekształcenie odwrotne, z szansy na prawdopodobieństwo wygląda następująco:
\[p_B = \frac{o_B}{o_B+1} = \frac{1}{1+o_G} \qquad p_G = \frac{o_G}{o_G+1} = \frac{1}{1+o_B}\]
Prawdopodobieństwa przyjmują wartości z przedziału \([0; 1]\), odpowiadające im szanse przyjmują wartości z przedziału \([0; +\infty)\)
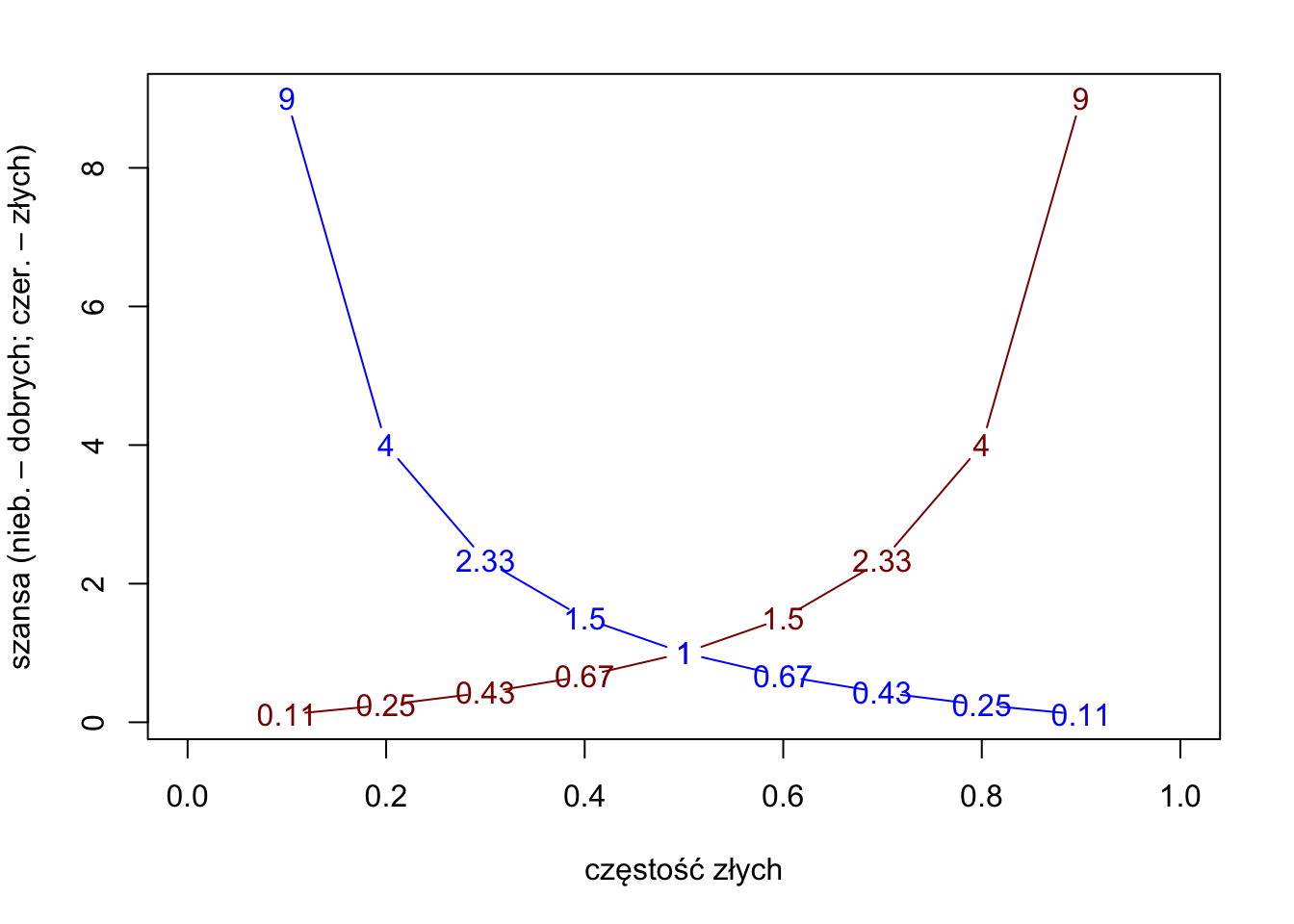
Rysunek 4.1: Prawdopodobieństwa z przedziału (0,1) i odpowiadające im szanse.
Czasem (np. w przypadku regresji logistycznej) używa się logarytmów szans (log-odds):
\[l_B = \ln{o_B} = \ln\frac{p_B}{1-p_B} = \ln\frac{p_B}{p_G}\]
Jak łatwo sprawdzić, spełniona jest równość:
\[l_B = -l_G\]
Funkcję \(f(x)=\ln\frac{x}{1-x}\) nazywa się funkcją logitową.
Odwrotne przekształcenia wyglądają tak7:
\[o_B = \exp(l_B)\]
\[p_B = \frac{\exp(l_B)}{1+\exp(l_B)} = \frac{1}{1+\exp(-l_B)} \]
Funkcję \(f(x) = \frac{1}{1+\exp(-x)}\) nazywa się funkcją logistyczną.
Prawdopodobieństwa przyjmują wartości z przedziału \([0; 1]\), odpowiadające im szanse przyjmuja wartości z przedziału \((-\infty; +\infty)\)
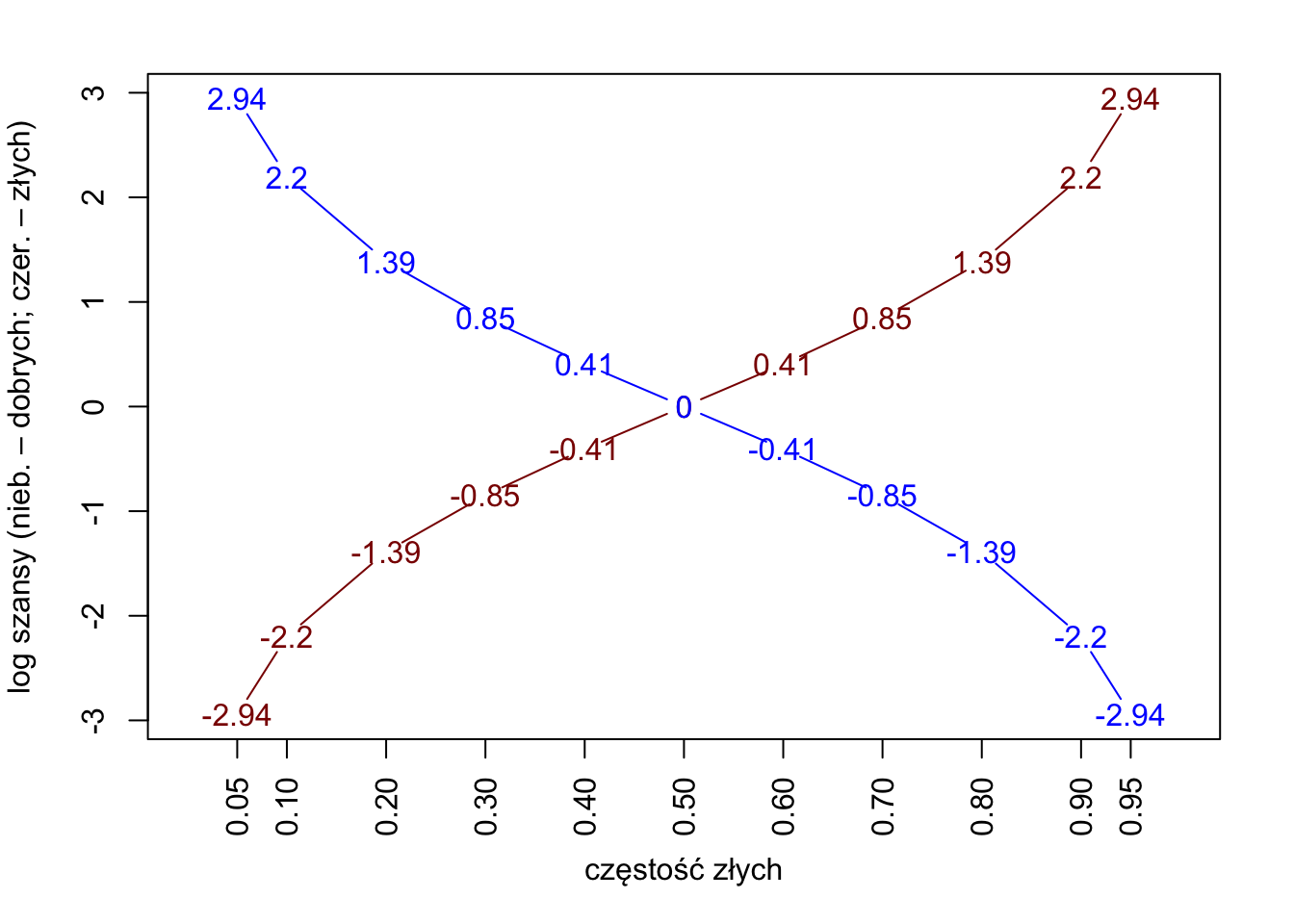
Rysunek 4.2: Prawdopodobieństwa z przedziału (0,1) i odpowiadające im logarytmy szans.
Zapis \(\exp(x)\) oznacza \(e^x\).↩︎