Chapter 6 Lecture 2017-01-24
6.1 Environmental Data
6.1.1 Data Science

6.1.2 Why Write a Computer Program?
- Accurate and fast math
- Written record of what you’ve done
- Facilitate collaboration
- Change parameters and re-run
- Repeatable analysis
- Reproducible science?
Ultimately writing a script will save you time and help you do better work
6.1.3 Today: R Computing
Today we’ll cover a “breathless tour” of R and some useful packages. For HW1, you will go on Data Camp and practice these ideas in an interactive setting where you get feedback.
- You don’t need to remember specific commands from today
- You should remember what is possible and why we might want to do it
We’ll save ~30 minutes for an in-class exercise. We almost certainly won’t get through all these slides – use them as a reference!
Slides will be posted – no need to write down every command. Ask questions!
6.2 Getting Started with R
6.2.1 R: Base plus Packages
“Base” R essential to know but has limited functionality. Packages add specific functionality:
“An R package is a collection of functions, data, and documentation that extends the capabilities of base R. Using packages is key to the successful use of R”
- R4DS
- Stored on Central R Archive Network (CRAN)
install.packages()library()or better yetrequire()- Many packages with overlapping goals \(\rightarrow\) many ways to do the same thing
6.2.2 Arithmetic
We use the +, -, * and / operators.
Exponents happen with ^ and modulo with %%.
R follows PEMDAS and you can use parentheses ()
## [1] 20## [1] 46.2.3 Assignment Best Practices
- Use
<-when you’re defining a variable (=works but is not recommended) - Use
=inside a function
6.2.4 Character Data
Not all data has to be numeric.
## [1] "character"Many functions only take a specific kind of data
## Error in sin(station_name): non-numeric argument to mathematical function6.2.5 Boolean Data
Use == for is equals to; use & for AND; use | for OR.
## [1] FALSE## [1] TRUE6.2.6 Vectors
Vectors are all the same data type.
We create them with c() function for concatenate
numeric_vector <- c(1, 10, 49)
character_vector <- c("a", "b", "c")
boolean_vector <- c(TRUE,FALSE,TRUE)Numerical operations work element-by-element on vectors
## [1] 1 100 24016.2.7 Vector Selection
We select data from a vector using element-wise indexing (starting at 1):
## [1] 10We can also use this to sub-set:
## [1] 3 6 9 12 15 18 216.2.8 List Data
Each element of a list can have any data type (including other lists)
TA <- list(name = 'James', UNI ='jwd2136', mental_age = 3,
is_nice = FALSE, idk = c(2, 3, 5, 7, 11))We access them with the $ operator
## [1] FALSE6.2.9 Matrices
## [,1] [,2]
## [1,] 1 3
## [2,] 2 4We can select matrix elements
## [1] 26.2.10 Matrix Math
To multiply matrices we use %*% and to transpose them we use ^T.
To invert a matrix, strangely, we use solve()
\[ \left( X^T X \right)^{-1} X^T y \] is written as
## [,1]
## [1,] -1
## [2,] 26.2.11 Data Frames
Data Frames and their extensions are the core of most R data analysis and where R excels. Think spreadsheet: each row is an observation and each column is a variable. For a data frame, each column is a vector (same data type) but a data frame can have columns of different data types
require(waterData)
sflow <- importDVs("05054000", sdate="2010-01-01", edate="2010-12-31")
head(sflow)## staid val dates qualcode
## 1 05054000 961 2010-01-01 A
## 2 05054000 954 2010-01-02 A
## 3 05054000 939 2010-01-03 A
## 4 05054000 922 2010-01-04 A
## 5 05054000 921 2010-01-05 A
## 6 05054000 910 2010-01-06 A6.2.12 Tibble
We’ll use tibble rather than data.frame structures because they have a few useful extensions.
Anything that works for a data.frame works for a tibble.
We can turn a data.frame into tibble
6.2.13 Creating Data Frames
We can read them from file or specify them by writing each column as a vector
6.2.14 Defining Functions
\(f(x) = \sin^2(x)\):
Make pretty histograms:
6.3 Statistical Computing
6.3.1 Generate Random Numbers
We use the rnorm, rbinom, rexp (see the pattern?) functions.
6.3.2 Get the PDF
x <- seq(0, 1, length.out = 1000)
binom_pdf <- dbinom(x=50, size=63, prob=x)
plot(x, binom_pdf, type='l', lwd=3, col='red',
main='Binomial PDF with 50 Success and 13 Fail')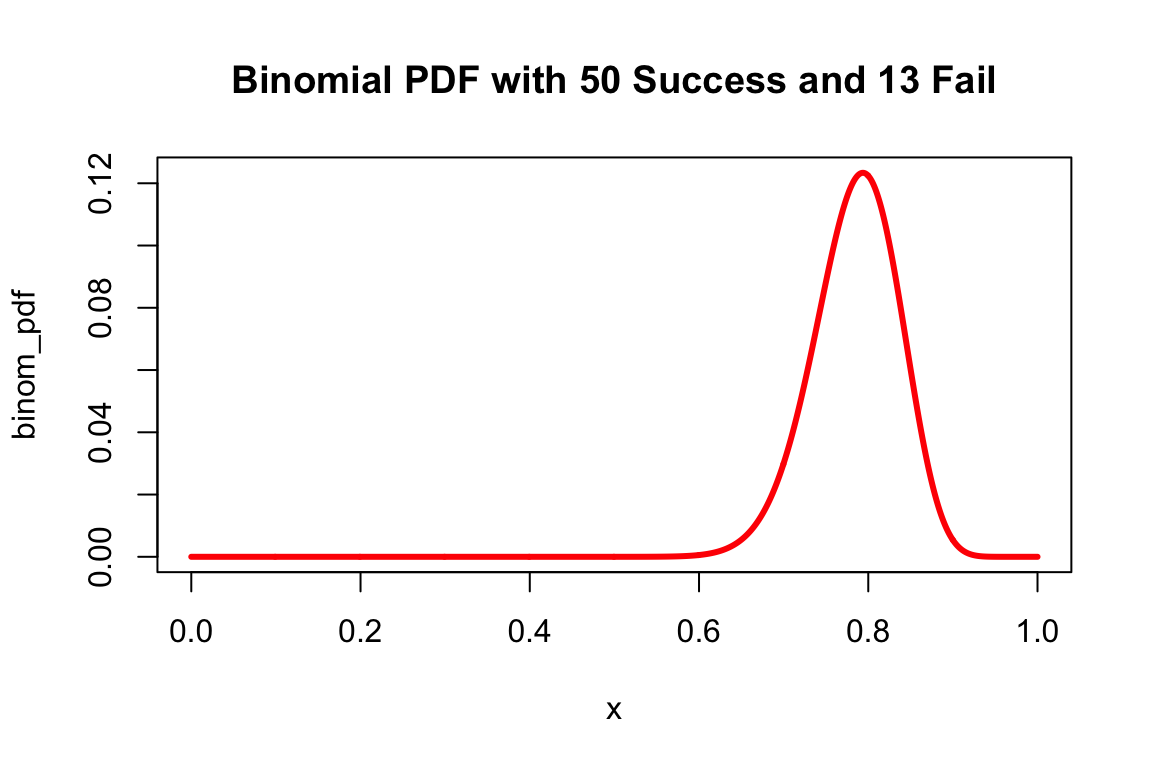
6.3.3 Other Functions
pnorm,pbinom, etc: CDFqnorm,qpois,qexpetc: inverse CDFexp,log,log10,sin,cos, etc
See http://seankross.com/notes/dpqr/ for more explanation and comparison
6.3.4 For Loops
They’re slow but useful – for example for bootstrap. For example, if we have 50 observations and want to estimate uncertainty in the mean:
6.3.5 For Loops and Density Plots
better_hist(boot_means, main='Boostrapped Sample Means')
abline(v=exp(2 + 0.5^2 / 2), lwd=3, col='red', lty=2)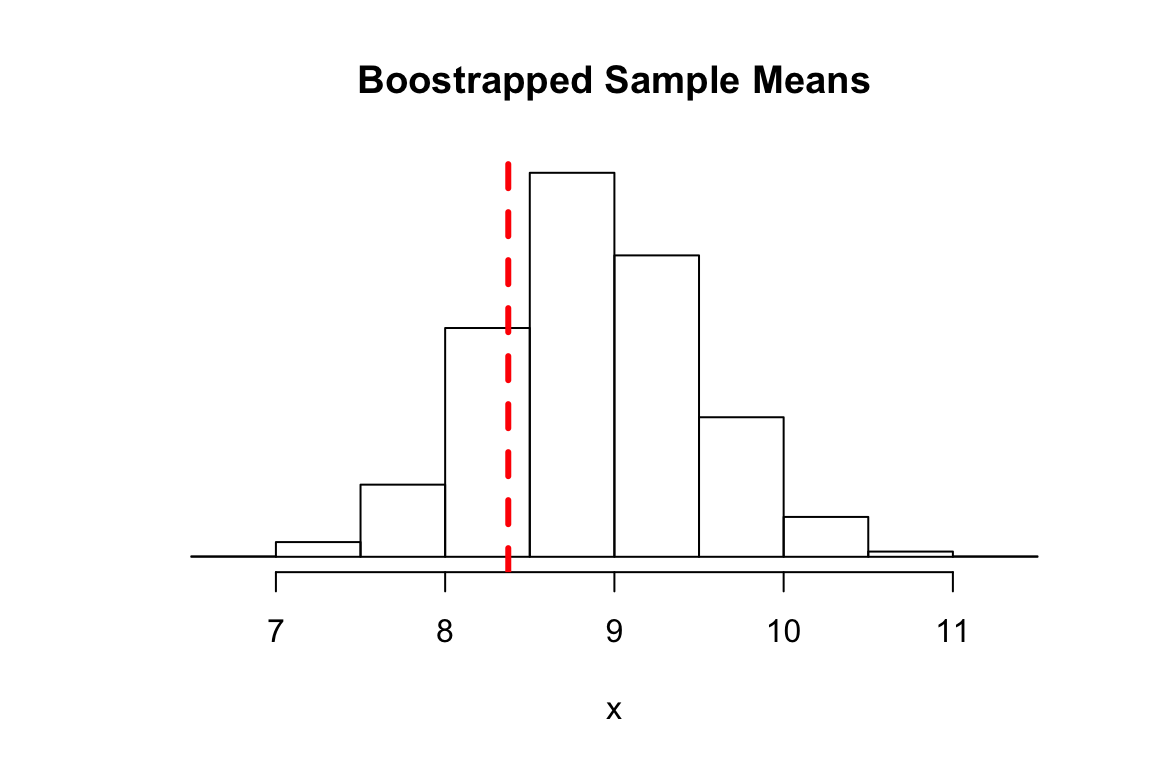
6.4 Data Wrangling
6.4.1 Tidy Data
- Easy to work with
- Each row is an observation, each column is a variable
- Think spreadsheet
- Lots of data is not tidy and you have to tidy it:
reshape2andtidyrpackages - We’ll make it easy for you this semester
6.4.2 The dplyr Package
Reduce operations on tibble objects to simple verbs:
select()select columnsfilter()filter rowsarrange()re-order or arrange rowsmutate()create new columnssummarise()summarise valuesgroup_by()allows for group operations in the “split-apply-combine” concept
6.4.3 Pipe Operator
The %>% operator lets us chain together long commands
## [1] 5.223517## [1] 4.3622736.4.4 For Example
6.4.6 DF to Vector
We can access elements of a data.frame or tibble with $ operator
## [1] 3004.838for complicated chains the pull() function can be useful
## [1] 3004.8386.5 Next Steps
6.5.1 Get Practicing

6.5.2 Your Courses
- Intro to R and
tidyverse - Data manipulation with
dplyr - Visualization with
ggplot2 - Reporting with
R Markdownso you can create analyses (like homeworks!)
6.5.3 RStudio
To write R you need a text editor on your computer and the R program installed.
RStudio is a IDE which lets you run code line by line, see results, format correctly, and more.
Highly recommended (though not strictly required) for the course.
6.6 Appendix
6.6.1 Some Best Practices
- Write functions!
- Use descriptive variable names:
flow_cfs\(>\)flow\(>\)yuusually - A style guide makes your code easier for you to read
- Do data exploration in
R Markdownfiles so you can explain what you are doing as you do it! - Code quality will be a [small! ~10%] part of grade for data analysis homeworks
6.6.2 Other Ways to Learn R
- Read my HW solutions
- Work in groups & read your classmates’ code
- Syllabus has some suggested blogs and twitter handles to follow – read the code & analysis of experts
- Stay positive!