33 Day 32 (July 25)
33.1 Announcements
- TEVALS
- Final presentations
- Send me an email (thefley@ksu.edu) to schedule a 20 min time interval for your final presentation. In your email give me three dates/times during the week of July 29 - July. 31 that work for you.
- Selected questions from journals
- “If I don’t have enough data to do any model checking, is it still appropriate (or even possible) to find prediction intervals and look at calibration?”
- “I understand the general idea of checking residuals for normality, I’m still unsure how to interpret the results in practice. For example, when residuals don’t look perfectly normal, I don’t yet have a clear sense of how much deviation is acceptable.”
- “I also find it hard to tell from the plots whether the residuals are”normal enough” or if the model is good. I’m not always sure how to interpret the results from normality tests or what to do if the assumption doesn’t hold.”
33.2 Distributional assumptions
Why did we assume \(\mathbf{y}\sim\text{N}(\mathbf{X\boldsymbol{\beta}},\sigma^{2}\mathbf{I})\)?
Is the assumption \(\mathbf{y}\sim\text{N}(\mathbf{X\boldsymbol{\beta}},\sigma^{2}\mathbf{I})\) ever correct? Is there a “true” model?
When would we expect the assumption \(\mathbf{y}\sim\text{N}(\mathbf{X\boldsymbol{\beta}},\sigma^{2}\mathbf{I})\) to be approximately correct?
- Human body weights
- Stock prices
- Temperature
- Proportion of votes for a candidate in an elections
Checking distributional assumptions
- If \(\mathbf{y}\sim\text{N}(\mathbf{X\boldsymbol{\beta}},\sigma^{2}\mathbf{I})\), then \(\mathbf{y} - \mathbf{X\boldsymbol{\beta}}\sim ?\)
If the assumption \(\mathbf{y}\sim\text{N}(\mathbf{X\boldsymbol{\beta}},\sigma^{2}\mathbf{I})\) is approximately correct, then what should \(\hat{\boldsymbol{\varepsilon}}\) look like?
Example: checking the assumption that \(\boldsymbol{\varepsilon}\sim\text{N}(\mathbf{0},\sigma^{2}\mathbf{I})\)
- Data
y <- c(63, 68, 61, 44, 103, 90, 107, 105, 76, 46, 60, 66, 58, 39, 64, 29, 37, 27, 38, 14, 38, 52, 84, 112, 112, 97, 131, 168, 70, 91, 52, 33, 33, 27, 18, 14, 5, 22, 31, 23, 14, 18, 23, 27, 44, 18, 19) year <- 1965:2011 df <- data.frame(y = y, year = year) plot(x = df$year, y = df$y, xlab = "Year", ylab = "Annual count", main = "", col = "brown", pch = 20) m1 <- lm(y ~ year, data = df) abline(m1)
- Histogram of \(\hat{\boldsymbol{\varepsilon}}\)
m1 <- lm(y ~ year, data = df) e.hat <- residuals(m1) hist(e.hat, col = "grey", breaks = 15, main = "", xlab = expression(hat(epsilon)))
- Plot covariate vs. \(\hat{\boldsymbol{\varepsilon}}\)

- A formal hypothesis test (see pg. 81 in Faraway (2014))
## ## Shapiro-Wilk normality test ## ## data: e.hat ## W = 0.86281, p-value = 5.709e-05Example: Checking the assumption that \(\boldsymbol{\varepsilon}\sim\text{N}\left(\mathbf{0},\sigma^{2}\mathbf{I}\right)\) (What it should look like)
- Simulated data
beta.truth <- c(2356, -1.15) sigma2.truth <- 33^2 n <- 47 year <- 1965:2011 X <- model.matrix(~year) set.seed(2930) y <- rnorm(n, X %*% beta.truth, sigma2.truth^0.5) df1 <- data.frame(y = y, year = year) plot(x = df1$year, y = df1$y, xlab = "Year", ylab = "Annual count", main = "", col = "brown", pch = 20)
## ## Call: ## lm(formula = y ~ year, data = df1) ## ## Residuals: ## Min 1Q Median 3Q Max ## -76.757 -22.237 3.767 19.353 66.634 ## ## Coefficients: ## Estimate Std. Error t value Pr(>|t|) ## (Intercept) 1717.2121 638.5293 2.689 0.0100 * ## year -0.8272 0.3212 -2.575 0.0134 * ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 ## ## Residual standard error: 29.87 on 45 degrees of freedom ## Multiple R-squared: 0.1285, Adjusted R-squared: 0.1091 ## F-statistic: 6.632 on 1 and 45 DF, p-value: 0.01337- Histogram of \(\hat{\boldsymbol{\varepsilon}}\)

- Plot covariate vs. \(\hat{\boldsymbol{\varepsilon}}\)

- A formal hypothesis test (see pg. 81 in Faraway (2014))
## ## Shapiro-Wilk normality test ## ## data: e.hat ## W = 0.98556, p-value = 0.8228Live example
33.3 Constant variance
If \(\mathbf{y}\sim\text{N}(\mathbf{X\boldsymbol{\beta}},\sigma^{2}\mathbf{I})\), then each \(\varepsilon_i\) follows a normal distribution with the same value of \(\sigma^2\).
- A linear model with constant variance is the simplest possible model we could assume. It is like the intercept only model in that regard.
- Example: Hubble data
## 2.5 % 97.5 % ## x 68.37937 84.78297# Plot data and E(y) plot(hubble$x,hubble$y,xlab="Distance (Mpc)", ylab=expression("Velocity (km"*s^{-1}*")"),pch=20) abline(m1)
# Plot residuals vs. x e.hat <- residuals(m1) hist(e.hat,col="grey",breaks=15,main="",xlab=expression(hat(epsilon)))

# Plot prediction intervals y.pi <- predict(m1,newdata=data.frame(x = 0:25),interval = "predict") plot(hubble$x,hubble$y,xlab="Distance (Mpc)", ylab=expression("Velocity (km"*s^{-1}*")"),xlim=c(0,25),ylim=c(0,2500),pch=20) points(0:25,y.pi[,2],typ="l",lwd=2,col="purple") points(0:25,y.pi[,3],typ="l",lwd=2,col="purple")
- A test for equal variance (see pg. 77 in Faraway (2014))
- What causes non-constant variance (also called heteroskedasticity).
What can be done?
- A transformation may work (see pg. 77 Faraway (2014))
- Build a more appropriate model for the variance. For example, \[\mathbf{y}\sim\text{N}(\mathbf{X\boldsymbol{\beta}},\mathbf{V})\] where the \(i^\text{th}\) and \(j^{th}\) entry of the matrix \(\mathbf{V}\) equals \[v_{ij}(\theta)=\begin{cases} \sigma^{2}e^{2\theta x_i} &\text{if}\ i=j\\ 0 &\text{if}\ i\neq j \end{cases}\]
## Generalized least squares fit by REML ## Model: y ~ x - 1 ## Data: hubble ## AIC BIC logLik ## 322.432 325.8385 -158.216 ## ## Variance function: ## Structure: Exponential of variance covariate ## Formula: ~x ## Parameter estimates: ## expon ## 0.1060336 ## ## Coefficients: ## Value Std.Error t-value p-value ## x 76.2548 3.854585 19.78288 0 ## ## Standardized residuals: ## Min Q1 Med Q3 Max ## -2.4272668 -0.4726915 -0.1548023 0.7929118 1.8437320 ## ## Residual standard error: 55.17695 ## Degrees of freedom: 24 total; 23 residual## 2.5 % 97.5 % ## x 68.69995 83.80965# Plot prediction intervals X <- model.matrix(y ~ x - 1, data = hubble) sigma2.hat <- summary(m1)$sigma^2 sigma2.hat * solve(t(X) %*% X)## x ## x 15.71959## x ## x 15.71959X <- model.matrix(y ~ x - 1, data = hubble) beta.hat <- coef(m2) sigma2.hat <- summary(m2)$sigma^2 theta.hat <- summary(m2)$modelStruct$varStruct V <- diag(c(sigma2.hat * exp(2 * X %*% theta.hat))) X.new <- model.matrix(~x - 1, data = data.frame(x = 1:25)) y.pi <- cbind(X.new %*% beta.hat - qt(0.975, 24 - 1) * sqrt(X.new^2 %*% solve(t(X) %*% solve(V) %*% X) + sigma2.hat * exp(2 * X.new %*% theta.hat)), X.new %*% beta.hat + qt(0.975, 24 - 1) * sqrt(X.new^2 %*% solve(t(X) %*% solve(V) %*% X) + sigma2.hat * exp(2 * X.new %*% theta.hat))) plot(hubble$x, hubble$y, xlab = "Distance (Mpc)", ylab = expression("Velocity (km" * s^{ -1 } * ")"), xlim = c(0, 25), ylim = c(0, 2500), pch = 20) points(1:25, y.pi[, 1], typ = "l", lwd = 2, col = "purple") points(1:25, y.pi[, 2], typ = "l", lwd = 2, col = "purple")
Example: Schizophrenia data
url <- "https://www.dropbox.com/scl/fi/y244p5qblopthh6nf5h8w/reaction_time.csv?rlkey=fvlqibqv990nzm957zy3qanxc&dl=1" df1 <- read.csv(url) head(df1)## time schizophrenia ## 1 312 no ## 2 272 no ## 3 350 no ## 4 286 no ## 5 268 no ## 6 328 noboxplot(time ~ schizophrenia, data = df1, xlab = "Schizophrenic", ylab = "Reaction time (in milliseconds)")
Example
- Linear model with constant variance
## ## Call: ## lm(formula = time ~ schizophrenia, data = df1) ## ## Residuals: ## Min 1Q Median 3Q Max ## -280.87 -70.17 -16.52 37.66 1207.13 ## ## Coefficients: ## Estimate Std. Error t value Pr(>|t|) ## (Intercept) 310.170 9.057 34.25 <2e-16 *** ## schizophreniayes 196.697 15.245 12.90 <2e-16 *** ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 ## ## Residual standard error: 164.5 on 508 degrees of freedom ## Multiple R-squared: 0.2468, Adjusted R-squared: 0.2453 ## F-statistic: 166.5 on 1 and 508 DF, p-value: < 2.2e-16- Plot residuals vs. predictor to check assumptions
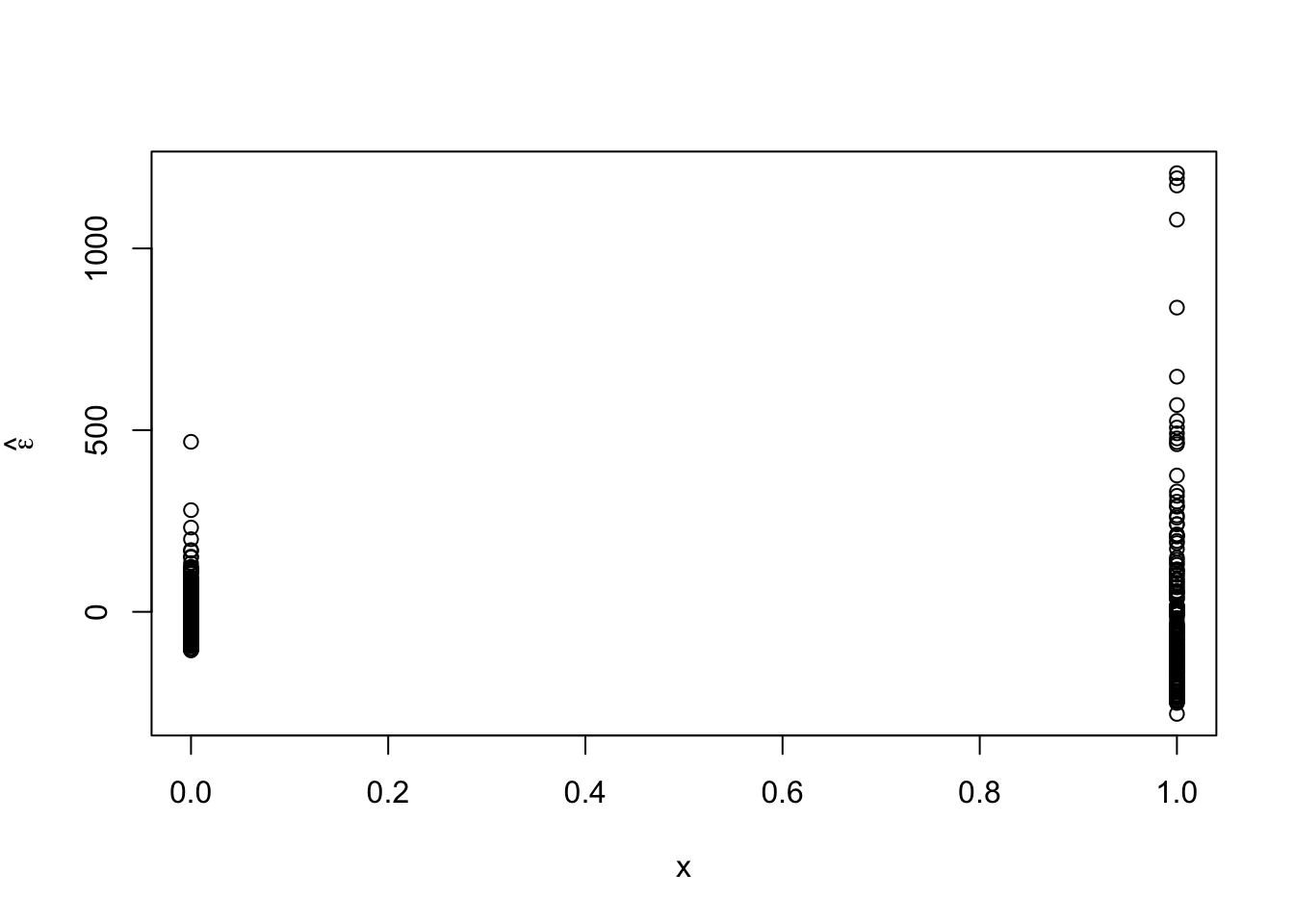
- Plot residuals for each category
par(mfrow = c(2, 1)) hist(e.hat[which(x == 0)], col = "grey", xlab = expression(hat(epsilon)), main = expression(hat(epsilon) * " for x = 0"), xlim = c(range(e.hat)), breaks = seq(min(e.hat), max(e.hat), length.out = 40)) hist(e.hat[which(x == 1)], col = "grey", xlab = expression(hat(epsilon)), main = expression(hat(epsilon) * " for x = 1"), xlim = c(range(e.hat)), breaks = seq(min(e.hat), max(e.hat), length.out = 40))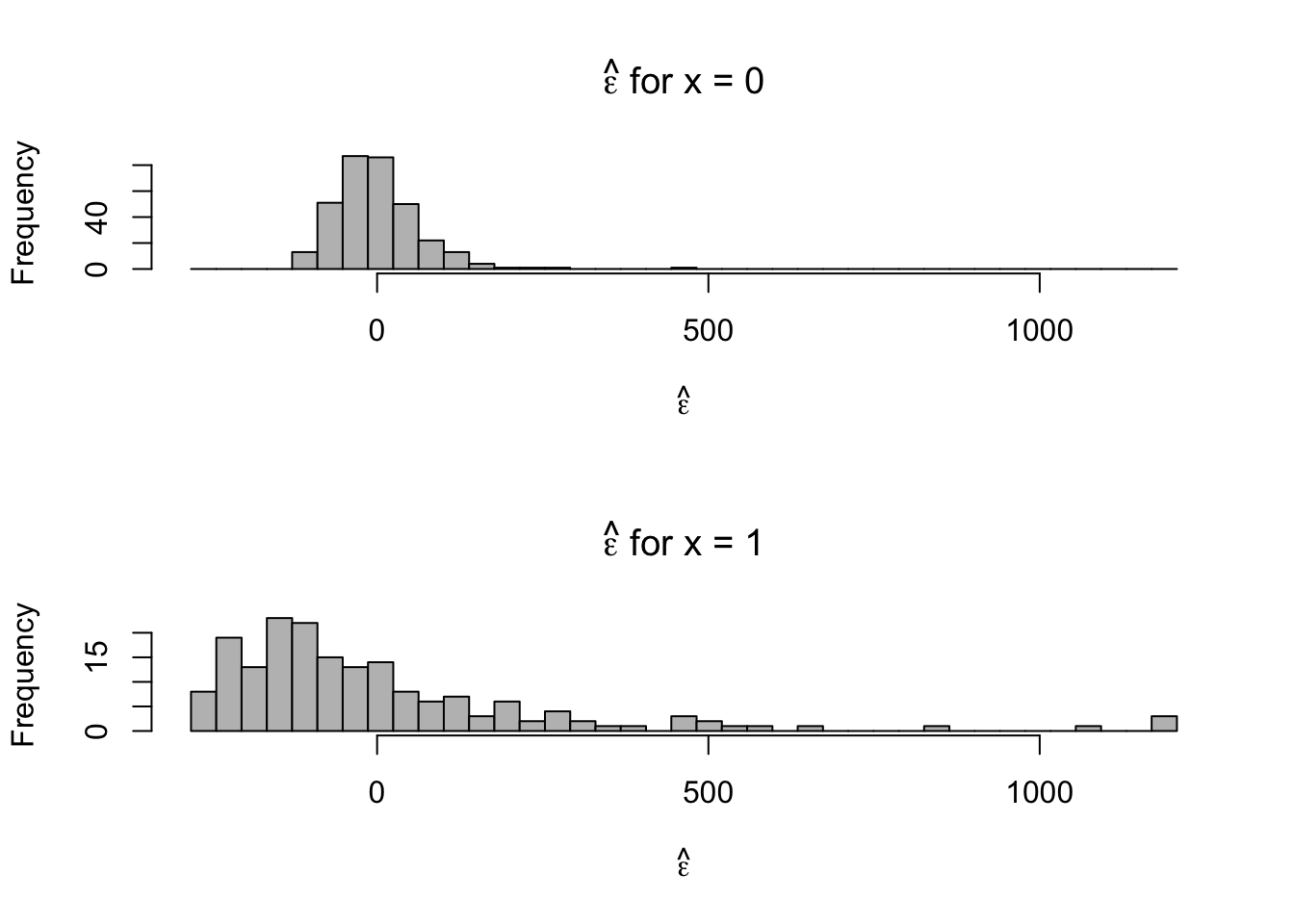
- Looks like there are some outliers due to skewness in the distribution of \(\mathbf{y}\) and the variance is not constant. Let’s tackle the problem of non-constant variance first.
- Some possible solutions
- Build a more appropriate model for the variance. For example, \[\mathbf{y}\sim\text{N}(\mathbf{X\boldsymbol{\beta}},\mathbf{V})\] where the \(i^\text{th}\) and \(j^{th}\) entry of the matrix \(\mathbf{V}\) equals \[v_{ij}(\theta)=\begin{cases} \sigma^{2}e^{2\theta x_i} &\text{if}\ i=j\\ 0 &\text{if}\ i\neq j \end{cases}\]
- For additional options see
?varClassesafter loading the nlme package in R. - Fit model using
?glsfunction
library(nlme) x <- ifelse(df1$schizophrenia == "no", 0, 1) m2 <- gls(time ~ schizophrenia, weights = varExp(form = ~x), method = "REML", data = df1) summary(m2)## Generalized least squares fit by REML ## Model: time ~ schizophrenia ## Data: df1 ## AIC BIC logLik ## 6200.793 6217.715 -3096.396 ## ## Variance function: ## Structure: Exponential of variance covariate ## Formula: ~x ## Parameter estimates: ## expon ## 1.399026 ## ## Coefficients: ## Value Std.Error t-value p-value ## (Intercept) 310.1697 3.571554 86.84447 0 ## schizophreniayes 196.6970 19.914372 9.87714 0 ## ## Correlation: ## (Intr) ## schizophreniayes -0.179 ## ## Standardized residuals: ## Min Q1 Med Q3 Max ## -1.6363885 -0.6461803 -0.1875710 0.4166345 7.2106463 ## ## Residual standard error: 64.8805 ## Degrees of freedom: 510 total; 508 residual## lower est. upper ## expon 1.270298 1.399026 1.527755 ## attr(,"label") ## [1] "Variance function:"# See ?varExp theta.hat <- m2$model[1]$varStruct * 2 sigma2.hat <- summary(m2)$sigma^2 sigma2.hat * exp(theta.hat * 0)## Variance function structure of class varExp representing ## expon ## 4209.479## Variance function structure of class varExp representing ## expon ## 69088.72## [1] 4209.479## [1] 69088.72# p-value from glm should be the same as t-test with unequal variances t.test(time ~ schizophrenia, alternative = c("two.sided"), mu = 0, var.equal = FALSE, data = df1)## ## Welch Two Sample t-test ## ## data: time by schizophrenia ## t = -9.8771, df = 190.98, p-value < 2.2e-16 ## alternative hypothesis: true difference in means between group no and group yes is not equal to 0 ## 95 percent confidence interval: ## -235.9773 -157.4166 ## sample estimates: ## mean in group no mean in group yes ## 310.1697 506.8667# Conclusiongs from var.test should match up with m2 var.test(time ~ schizophrenia, alternative = c("two.sided"), data = df1)## ## F test to compare two variances ## ## data: time by schizophrenia ## F = 0.060929, num df = 329, denom df = 179, p-value < 2.2e-16 ## alternative hypothesis: true ratio of variances is not equal to 1 ## 95 percent confidence interval: ## 0.04683408 0.07847916 ## sample estimates: ## ratio of variances ## 0.0609286- Plot residuals vs. predictor to check assumption
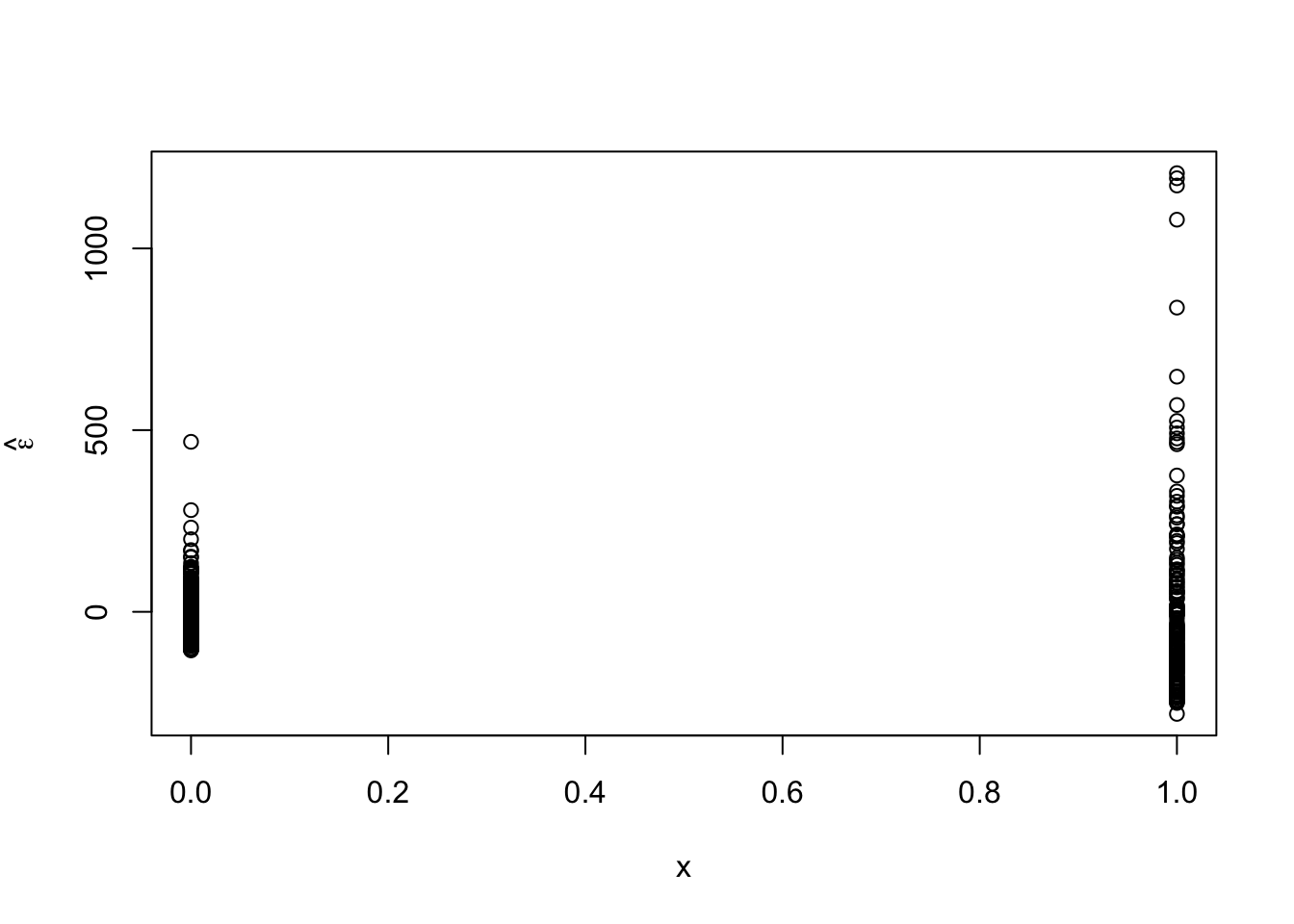
- Plot residuals for each category
par(mfrow = c(2, 1)) hist(e.hat[which(x == 0)], col = "grey", xlab = expression(hat(epsilon)), main = expression(hat(epsilon) * " for x = 0"), xlim = c(range(e.hat)), breaks = seq(min(e.hat), max(e.hat), length.out = 40)) hist(e.hat[which(x == 1)], col = "grey", xlab = expression(hat(epsilon)), main = expression(hat(epsilon) * " for x = 1"), xlim = c(range(e.hat)), breaks = seq(min(e.hat), max(e.hat), length.out = 40))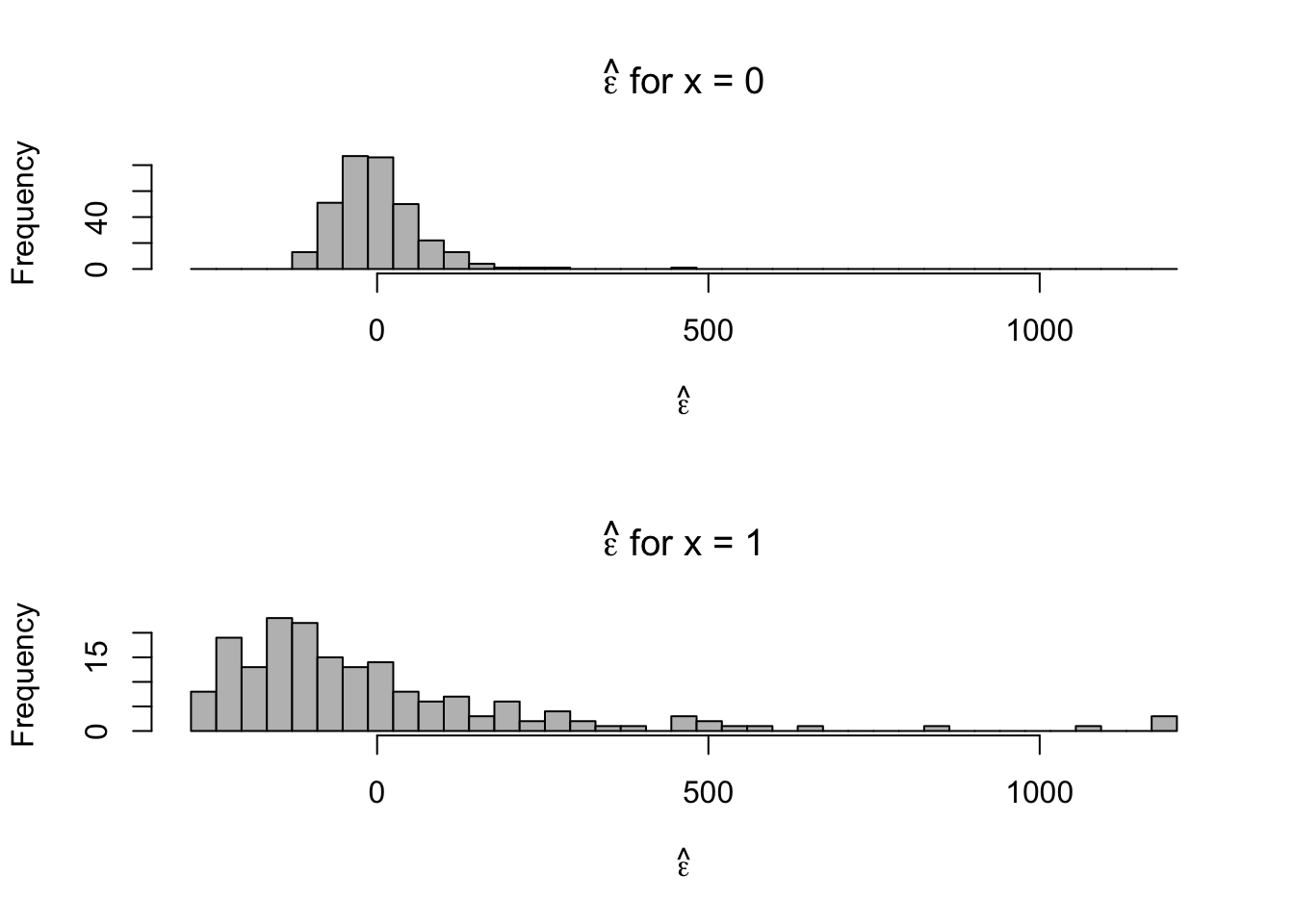
- Normal distribution is symmetric, the support of reaction times is always positive. We probably won’t be able to alleviate the issue of skewness using the normal distribution.