2.1 Estadística descriptiva: Medidas de tendencia central y dispersión en eventos de riesgo.
2.1.1 Características de los datos
Localización: es la posición relativa que presentan un conjunto de datos. En general, se mide por el punto medio del conjunto de datos.
Dispersión: Los valores obtenidos en una muestra no son todos iguales. La variación entre estos valores se denomina dispersión. Se trata de detectar el grado de discrepancia entre los datos individuales al rededor del centro de las observaciones.
Simetría y asimetría: Son simétricos cuando los datos están distribuidos de la misma manera sobre y debajo del punto medio. En los asimétricos hay más agrupamiento de un lado del punto medio.
2.1.2 Distribución de frecuencias
Es la agrupación de datos en categorías mutuamente excluyentes que indican el número de observaciones en cada categoría. Esto proporciona un valor añadido a la agrupación de datos. La distribución de frecuencias presenta las observaciones clasificadas de modo que se pueda ver el número existente en cada clase.
Se puede elaborar una tabla de frecuencias para datos nominales y ordinales. Si los datos son continuos, ¿Qué debemos hacer?
2.1.2.1 Elaboración de una tabla de frecuencias
Supongamos que tenemos un conjunto de \(n\) datos, que toman \(k\) valores distintos: \(x_1,x_2,,\ldots,x_k\).
Se ordena los \(x_i\) datos en una columna de forma ascendente y se cuenta cuántas veces aparece cada valor, ésta es su frecuencia absoluta \(n_i\) que se coloca en una columna contigua. Note que \(\sum_{i=1}^{k}n_i=n\).
Una tercera columna tiene la frecuencia relativa \(f\) que resulta de \(f_i = \frac{n_i}{n}\). Note que verse como un porcentaje.
Se pueden agregar dos columnas más, de las frecuencias acumuladas absoluta y relativa respectivamente.
Es decir:
| Valor de la variable (\(x_i\)) | Frec. Absoluta (\(n_i\)) | Frec. Relativa (\(f_i = \frac{n_i}{n}\)) | Fre. Abs. Acumulada (\(N_i\)) | Frec. Rel. Acumulada (\(F_i\)) |
|---|---|---|---|---|
| \(x_1\) | \(n_1\) | \(f_1\) | \(N_1 = n_1\) | \(F_1=f_1\) |
| \(x_2\) | \(n_2\) | \(f_2\) | \(N_2 = N_1+n_2\) | \(F_2 = F_1+f_2\) |
| \(\vdots\) | \(\vdots\) | \(\vdots\) | \(\vdots\) | \(\vdots\) |
| \(x_k\) | \(n_k\) | \(f_k\) | \(N_k = N_{k-1}+n_k\) | \(F_k = F_{k-1}+f_k\) |
| TOTAL | n | 1 |
Ejemplo para variable discreta y continua
2.1.3 Representaciones gráficas de los datos
2.1.3.1 Gráfico de sectores y de barras
Ambos suelen usarse para representar gráficamente datos nominales u ordinales.
- El gráfico de sectores (pastel) es un círculo dividido en segmentos donde cada uno de los sectores es proporcional a la frecuencia relativa de esa categoría.
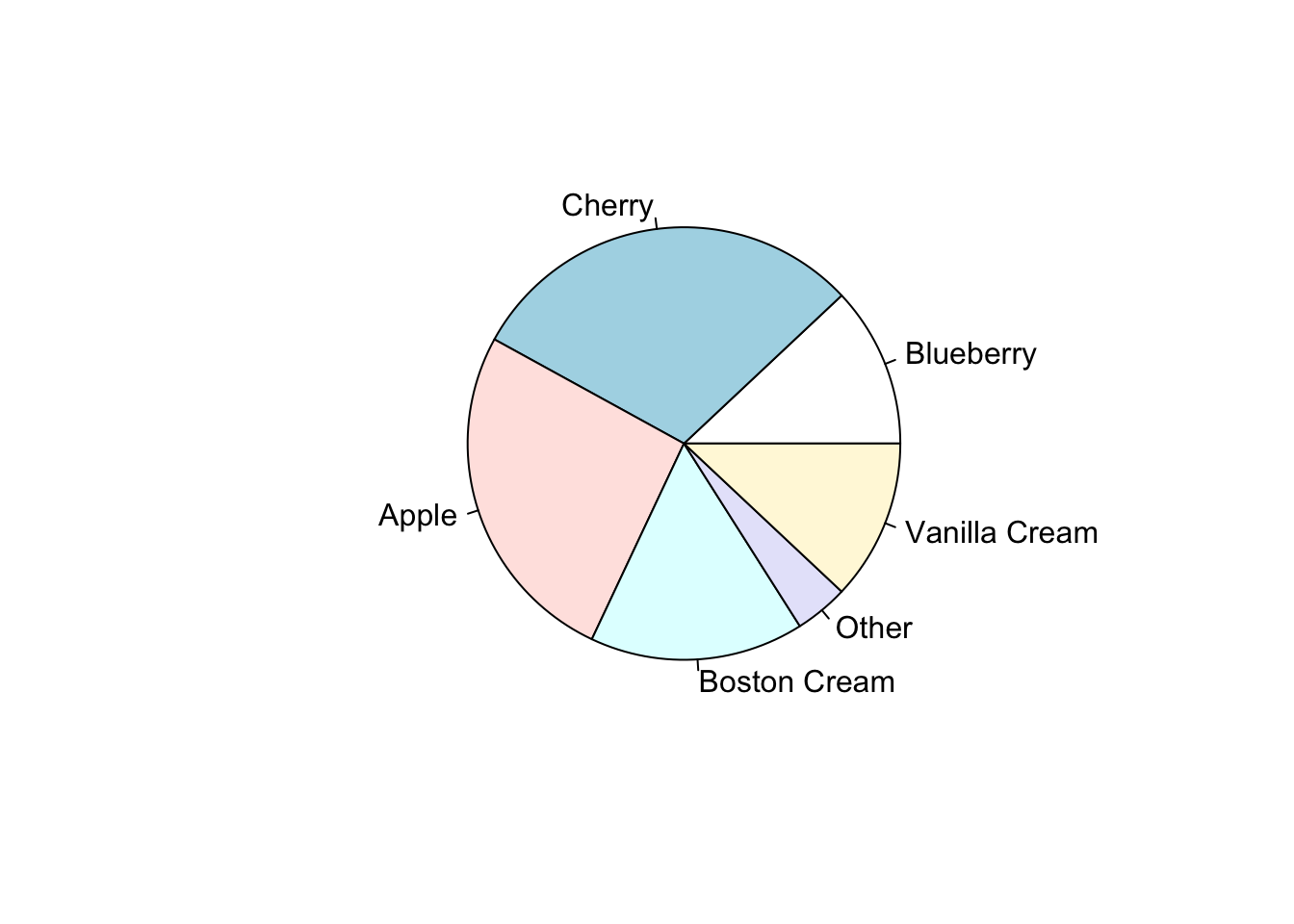
- El gráfico de barras se muestra mediante recángulos del mismo ancho, cada uno de los cuales representa una categoría. La longitud (y por tanto el área) de cada uno es proporcional al número de casos que representa.
Si la variable tiene orden, se respecta en el gráfico.Pueden darse como filas o columnas.
Ejemplo: representar los siguientes datos como gráfico de sectores y barras:
## Marca N.Respuestas Porcentaje
## 1 Toshiba 135 42
## 2 Dell 76 23
## 3 HP 53 16
## 4 Lenovo 43 13
## 5 No sabe 19 6
2.1.4 Medidas de locación
Ante un conjunto de observaciones, es de interés el valor en torno al cual se agrupan la mayoría o el centro del conjunto. Las medidas que permiten hacerlo se llaman medidas de localización o medidas de tendencia central.
2.1.4.1 Media
Promedio o media: notado como \(\bar{x}\), de un conjunto de \(n\) datos \(x_1,x_2,\ldots,x_n\) es igual a la suma de valores dividido para \(n\).
\[ \bar{x} = \frac{x_1+x_2+\ldots+x_n}{n}=\frac{\sum_{i=1}^nx_i}{n} \]
- Si las observaciones están agrupadas en una tabla de frecuencia de datos individuales de \(k\) valores, el promedio se calcula
\[ \bar{x} =\frac{\sum_{i=1}^kn_ix_i}{n} \] donde \(n = {\sum_{i=1}^kn_i}\).
- Si las observaciones están agrupadas en una tabla de frecuencias agrupadas por clases, se calcula el punto promedio de cada clase \(x_i = \frac{l_i+s_i}{2}\) (\(i = 1,2,\ldots,k\)), donde \(l_i\) y \(s_i\) son la cota inferior y superor de cada clase respectivamente. El promedio es
\[ \bar{x} =\frac{\sum_{i=1}^kn_ix_i}{n} \]
Ventajas y desventajas del promedio:
- Se expresan en las mismas unidades quela variable
- En su cálculo intervienen todos los valores de la distribución
- Es el centro de gravedad de toda la distribución
- Es único
- Su principal inconveniente es que se ve afectado por valores atípicos
2.1.4.2 Mediana
La mediana de un conjunto de datos \(x_1+x_2+\ldots+x_n\) es el valor que se encuentra en el punto medio, cuando se ordenan los valores de menor a mayor.
Se nota como \(Q_2\) o Med y tiene la propiedad de que a cada lado se encuentra el 50% de los datos.
Si los datos están están resumidos en una tabla de distribución de frecuencias por clases:
\[ Med = L_{i-1}+\frac{n/2-N_{i-1}}{n_i}A \]
Ejemplo:
| Ingreso anual | Numero de personas (\(n_i\)) | Frecuencia acumulada (\(N_i\)) |
|---|---|---|
| 6800-8000 | 3 | 3 |
| 8000-10400 | 20 | 23 |
| 10400-12800 | 35 | 58 |
| 12800-16500 | 25 | 83 |
| 16500-20000 | 15 | 98 |
| 20000-26000 | 2 | 100 |
\[ Med = 10400+\frac{100/2-23}{35}(2400) = 12251 \]
2.1.4.3 Moda
Es el valor que tiene la mayor frecuencia absoluta
Se la nota como Mo. Para calcularla es últil realizar una tabla de frecuencia de los datos.
Si los datos están están resumidos en una tabla de distribución de frecuencias por clases:
\[ Mo = L_{i-1}+\frac{d1}{d1+d2}A \]
Usando los datos de la tabla anterior:
\[ Mo = 10400+\frac{35-20}{(35-20)+(35-25)}2400=11840 \]
2.1.4.4 Media geométrica
Notada como \(\bar{MG}\) de un conjunto de \(n\) mediciones \(x_1+x_2+\ldots+x_n\), es igual a la raíz enésima de su producto. Es decir,
\[ \bar{MG} = (x_1\times x_2\times\ldots\times x_n)^{1/n} \]
Si las observaciones están agrupadas en una tabla de frecuencias de datos individuales,
\[ \bar{MG} = (x_1^{n_1}\times x_2^{n_2}\times\ldots\times x_k^{n_k})^{1/n} \]
Si los datos están agrupados por clases, el cáculo es el mismo anterior, pero \(x_i\) es el punto medio de la clase.
Tiene las mismas ventajas de la media, pero
- Es menos sensible a datos atípicos
- Solo se puede calcular cuando hay datos positivos
- Se recomienda su uso cuando la variable presenta variacionas acumuladas: porcentajes, tasas de variación.
2.1.4.5 Cuantiles
Un cuantil divide la distribución de los datos en una proporción específica, el cuantil es el dato que corresponde a dicha división.
El cuantil de orden \(p\) de una distribución (con \(0 < p < 1\)) es el valor de la variable \(x_{p}\) que marca un corte de modo que una proporción \(p\) de valores de la población es menor o igual que \(x_{p}\). Por ejemplo, el cuantil de orden \(0.36\) dejaría un 36% de valores por debajo y el cuantil de orden \(0.50\) se corresponde con la mediana de la distribución.
Los cuantiles suelen usarse por grupos que dividen la distribución en partes iguales; entendidas estas como intervalos que comprenden la misma proporción de valores. Los más usados son:
- Los cuartiles, que dividen a la distribución en cuatro partes (corresponden a los cuantiles \(0.25\); \(0.50\) y \(0.75\));
- Los quintiles, que dividen a la distribución en cinco partes (corresponden a los cuantiles \(0.20\); \(0.40\); \(0.60\) y \(0.80\));
- Los deciles, que dividen a la distribución en diez partes;
- Los percentiles, que dividen a la distribución en cien partes.
2.1.5 Medidas de dispersión
Estas medidas permiten estimar el grado de dispersión de las observaciones al rededor del centro.
Son números reales no negativos, su valor es igual a cero cuando los datos son iguales. Si los datos están muy grupados, la medida será baja; será alta caso contrario.
2.1.5.1 La desviación estándar
Fue introducida por Karl Person en 1894 y se define:
La desviación estándar (o desviación típica), notada por \(s\), de un conjunto de \(n\) mediciones \(x_1+x_2+\ldots+x_n\) es la raíz cuadrada de las desviaciones de las mediciones, respecto al promedio \(\bar{x}\), dividida entre \(n-1\); es decir
\[ s = \sqrt{\frac{1}{n-1}\sum_{i = 1}^{n}(x_i-\bar{x})^2} \]
- Se expresa en las mismas unidades que los datos originales
- En su cálculo intervienen todos los valores de la distribución
- Es única
- Se ve afectada por valores atípicos